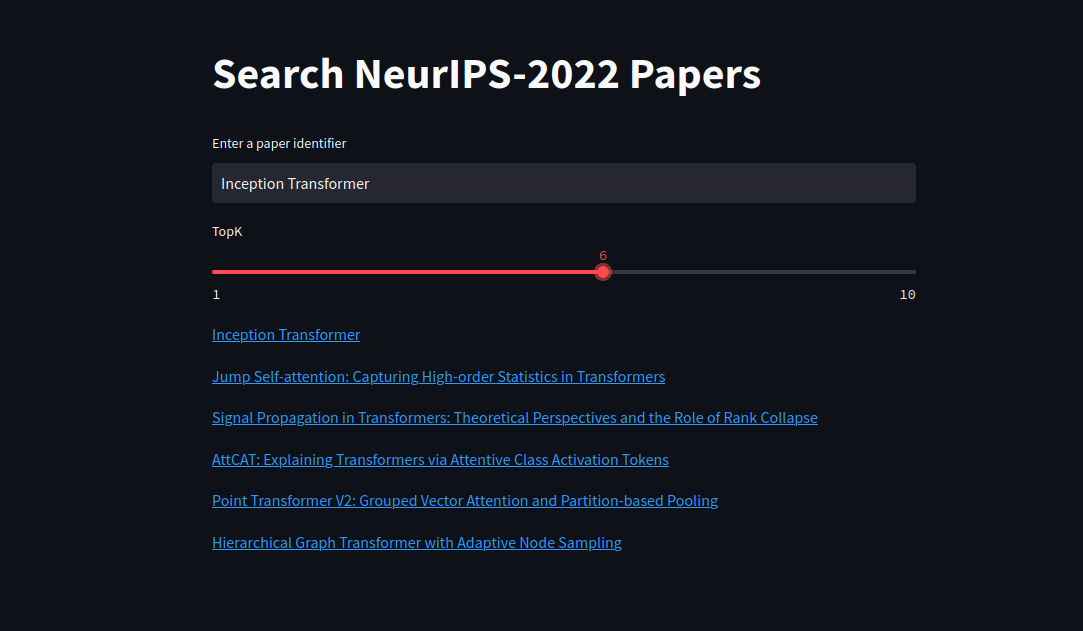
Search NeurIPS-2022 Similar Papers
This article is about simplifing the steps of achieving similar document retrieval and deploying it in Streamlit app. Sentences are embedded with S-BERT and indexed using Annoy Index.
Gather data
Here, BeautifulSoup library is used in scraping the NeurIPS-2022 papers. While thinking of scraping, the url of each paper is changing with respect to unique event id. So, It was easier to get the each paper information.
Gathered information :
- Title : Research paper title
- Abstract : Abstract of paper
- paper url : link to the paper
- paper url id : url link id to acces the paper from id.
How data looks,

Sentence embeddings
Using SentenceTransformers we can get the embeddings of sentence, SentenceTransformers is a Python framework for getting text and image embeddings.
we have \(\textbf{title}\) and \(\textbf{abstract}\) as input, join and create a single input and get the embeddings using SentenceTransformers library, pretrained weights of Sci-BERT(pritamdeka/S-Scibert-snli-multinli-stsb) is used to get better representation of scientific papers.
Annoy
Using embeddings, Annoy indexes papers based on the trees.
It will inspect up to search \(k\) nodes during the query and gives the topk indexes.
Since we have embeddings, instead of word index, Annoy has method to search based on vector ie, getnnsbyvector and returns the closest k items.
Web app
I have created web app using streamlit. It gives topk nearest neighbors of research papers.