Sentiment Classification and Word Embeddings

Exploratory Data Analysis : IMDB Dataset
Sample dataset
We use binary classification dataset, Internet Movie Database (IMDB), to classify positive or negative from the reviews. IMDB data contains 50K reviews or complaints for total of two categories, namely “positive” and “negative”.
The data is accessible from this link.
The first thing data scientist do is look at the data. Feel out some basic questions on dataset like, what kind of data it is? how to handle? how big the data is? Is data clean? or need any preprocessing?
Load the dataset
1
dataset = pd.read_csv("yourfilename.csv")
Sample reviews :
1
dataset.head()

Properties of dataset
Shape of dataset
1
print(f'Number of Rows : {dataset.shape[0]}\nNumber of Columns : {dataset.shape[1]}')
1
2
Number of Rows : 50000
Number of Columns : 2
Statistics on text
1
dataset.info()
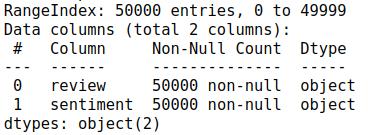
There are two columns, review and sentiment, with samples 5000.
1
dataset.describe()

By observation, there are 50k counts/samples, have two unique labels/classes (postive/negative).
there are 5 samples frequently occured, which means, repeated reviews. Let’s see them,
1
Counter(dataset.review).most_common(2)

we can see the review are duplicated.
1
dataset.drop_duplicates(['review','sentiment'],inplace=True)
we have succesfully removed duplicates.
1
print(f"Number of Rows : {dataset.shape[0]}\nNumber of Columns : {dataset.shape[1]}")
1
2
Number of Rows : 49582
Number of Columns : 2
Human make mistakes,It is inevitable part of being human.

People may forget to give feedbacks/reviews.
Checking missing values.
1
dataset.isnull().sum()
1
2
review 0
sentiment 0
Number of reviews per classes
How many reviews are Positive/Negative class. sentiment
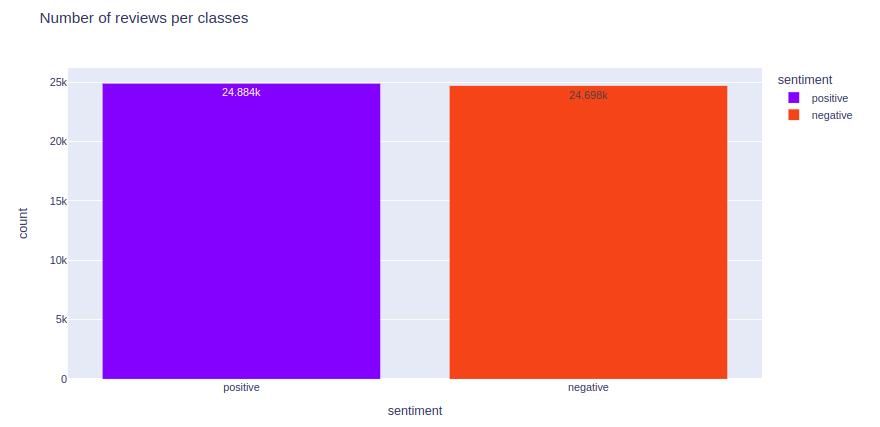
Above graph shows us distribution is 24.88k and 24.69K, for postive and negative classes, respectively.
Are there any words follows with # tags?
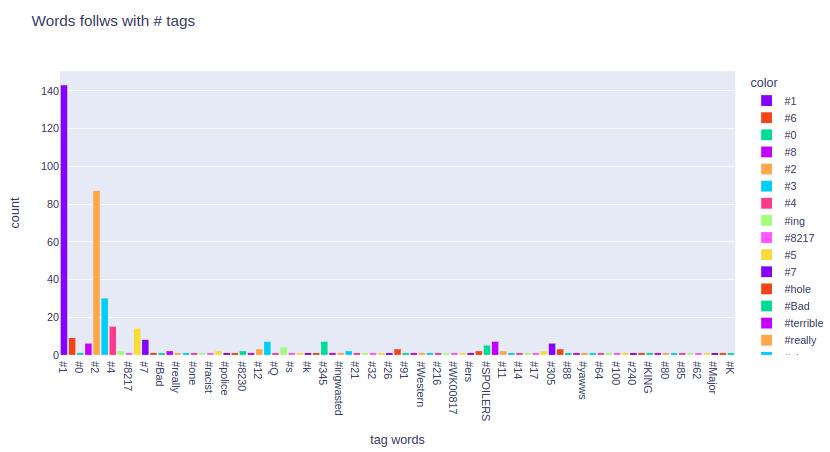
There are 83 # taged words present. let’t clean them.
1
2
3
4
5
6
def clean_text(text):
pattern = r****'(\#\w+)'
text = re.sub(pattern,"",text)
return text
dataset.review = dataset.review.apply(lambda x : clean_text(x))
Positive Review Text
Representing positive review text data in which the size of each word indicates its frequency
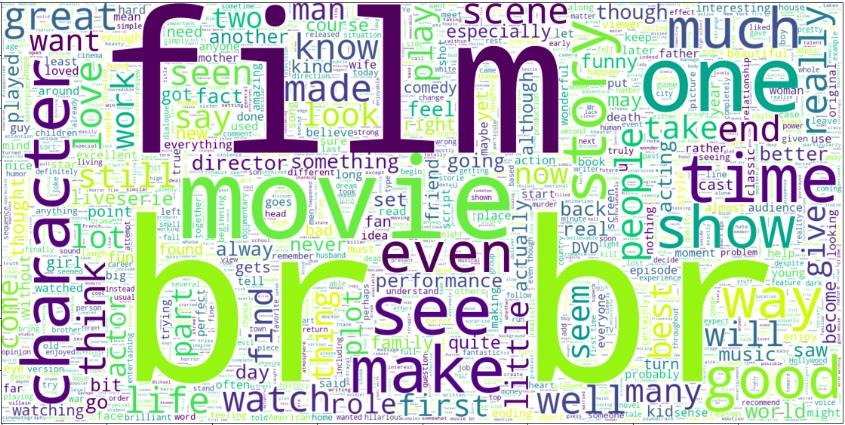
Word “br” is indicating more frequency. which is no use, We need to clean.
Negative Review Text
Representing positive review text data in which the size of each word indicates its frequency
In negative review also Word “br” is indicating more frequency, We need to clean.
Reviews samples
Number of words in each reviews
1
dataset['review_len'].describe()
1
2
3
4
5
6
7
8
count 50000.000000
mean 231.156940
std 171.343997
min 4.000000
25% 126.000000
50% 173.000000
75% 280.000000
max 2470.000000
longest review has 2470 words, whereas shortest has 4 words.
75% of review data has less words (approximately 280).
1
print(f"Max word review length is {list(df['review_len'])[0]}")
1
Max word review length is 2470
1
print(f"Minimun word review length is {list(df['review_len'])[0]}")
1
Minimun word review length is 4
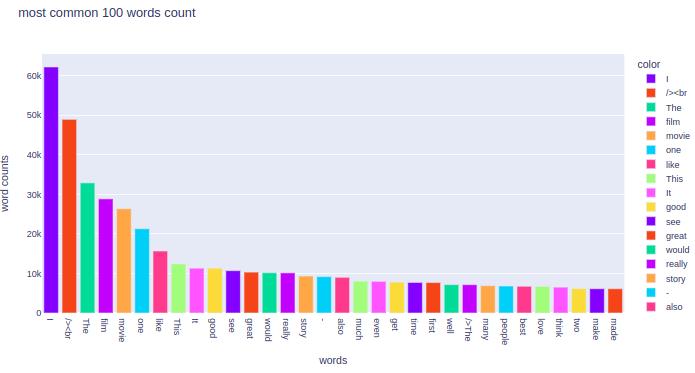
Most common words
Here are the 100 most common words.
Average word length in text (positive and negative review)
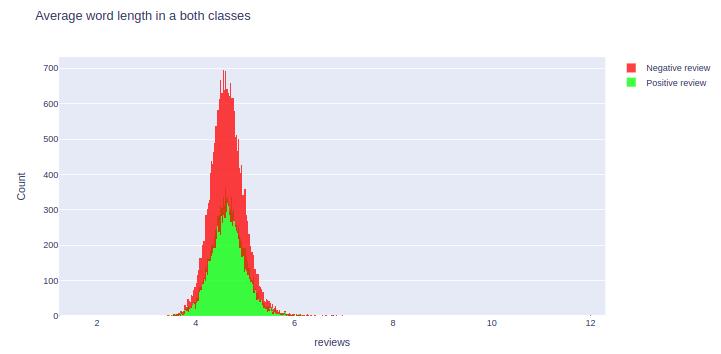
Negative average word length are more, than positive average word length.
Let’s talk about model
Using nn.Embedding randomly intialized embeddings.
We have two embedding vectors, one is from the nn.Embedding trained embedding vectors and another is word trained using gensim library to get the vectors of words, Which is used to train our model.
Model architecture
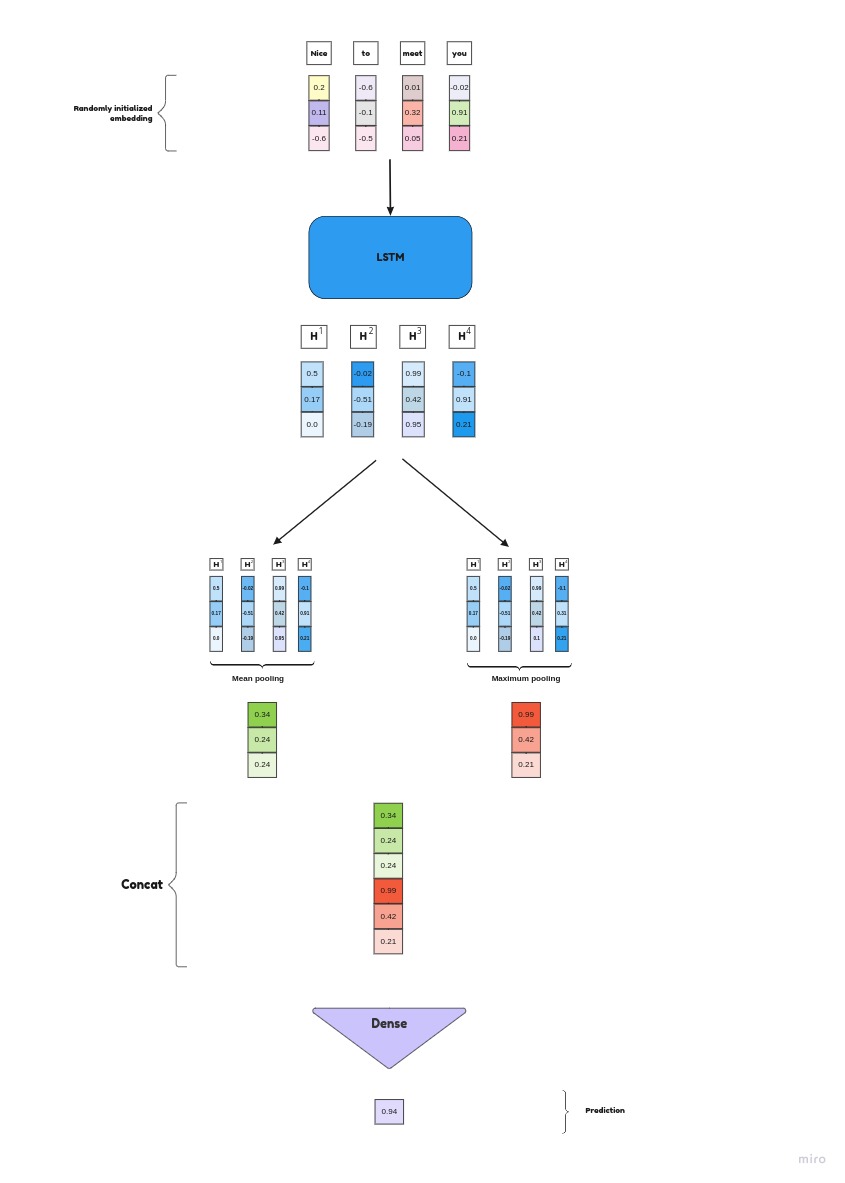
Here Embeddings are randomly intialized and trained.
sequence of tokens(sentence) will be sent to embedding layer of nn.Embedding, Itself creates embeddings to each vectors as shown here.
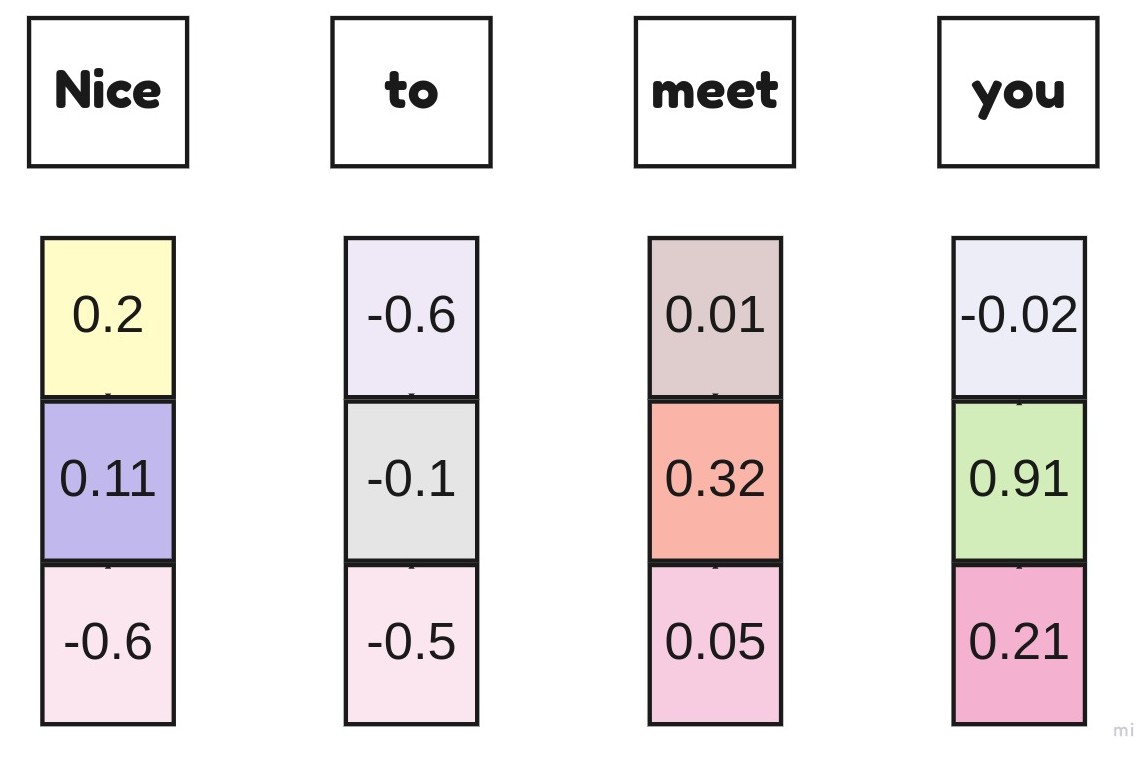
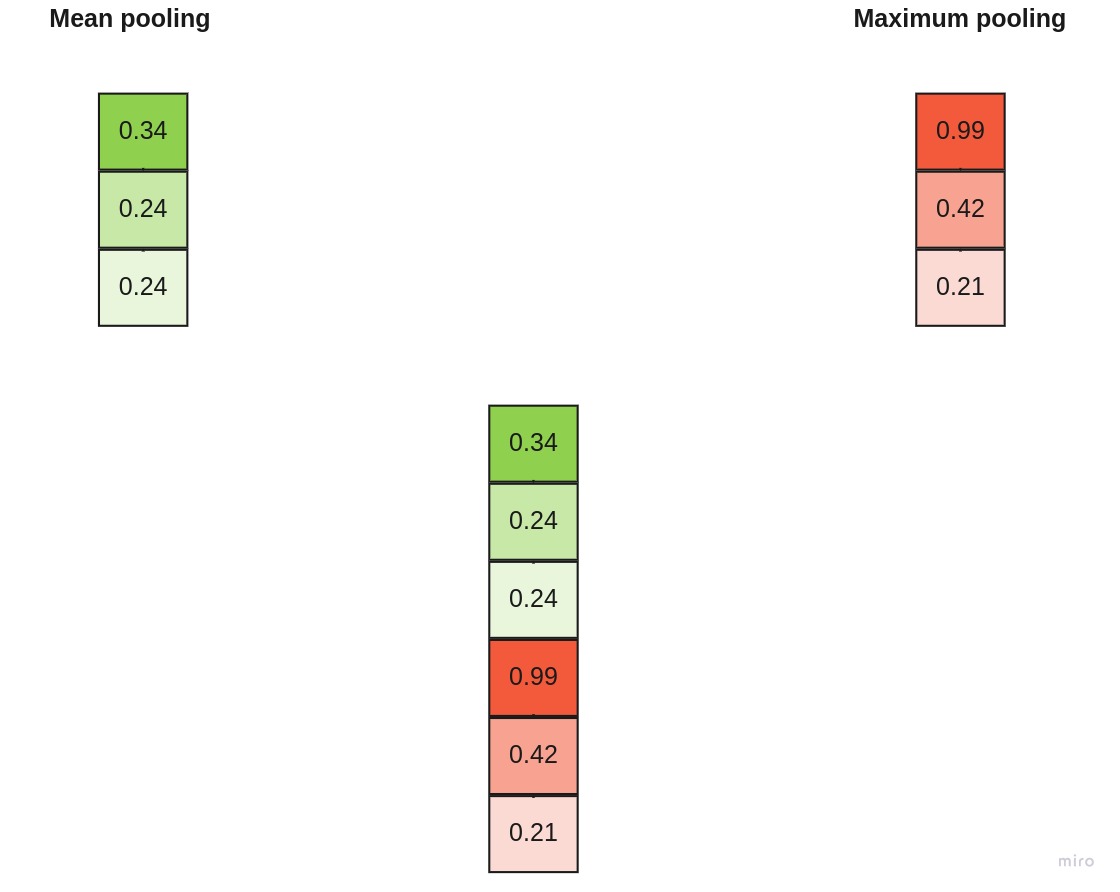
These vectors are sent to LSTM model, and returns hidden state vectors. returned hidden state vectors are concatinated of mean pooled hidden state and max pooled hidden state.
 Concatinated are sent to linear/Dense layer for decisions.
Concatinated are sent to linear/Dense layer for decisions. 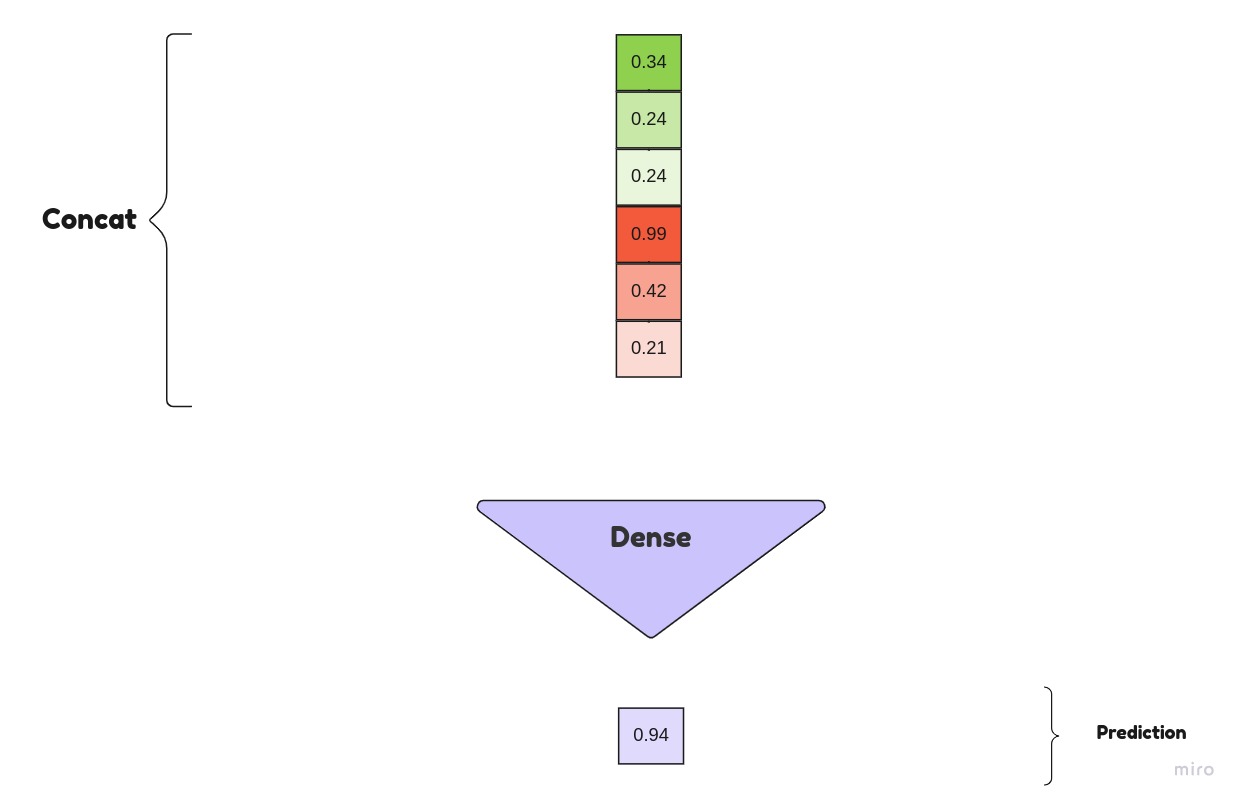
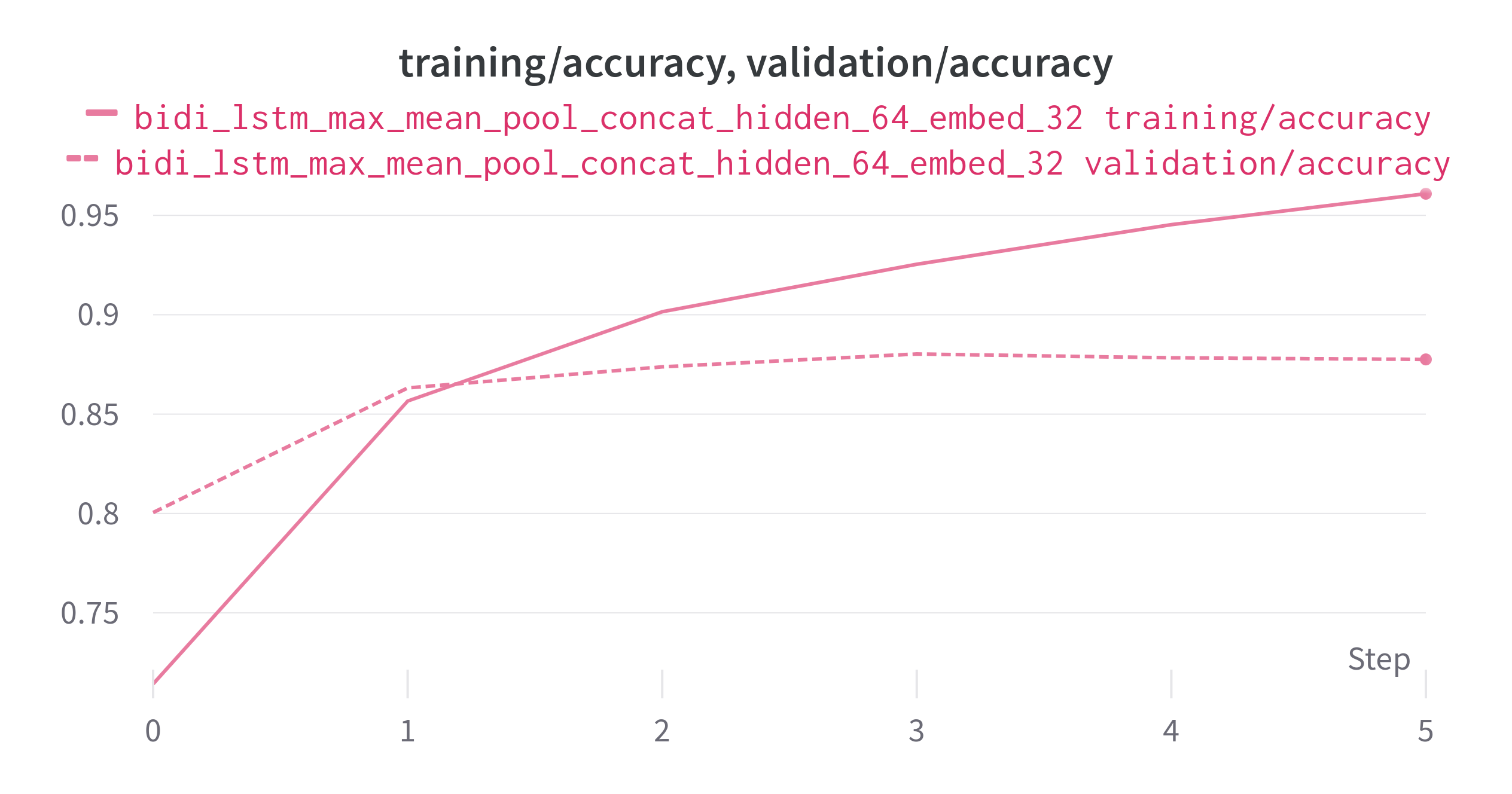
I have tranined model taking embedding size to 32. Below are my result
Accuracy
Loss
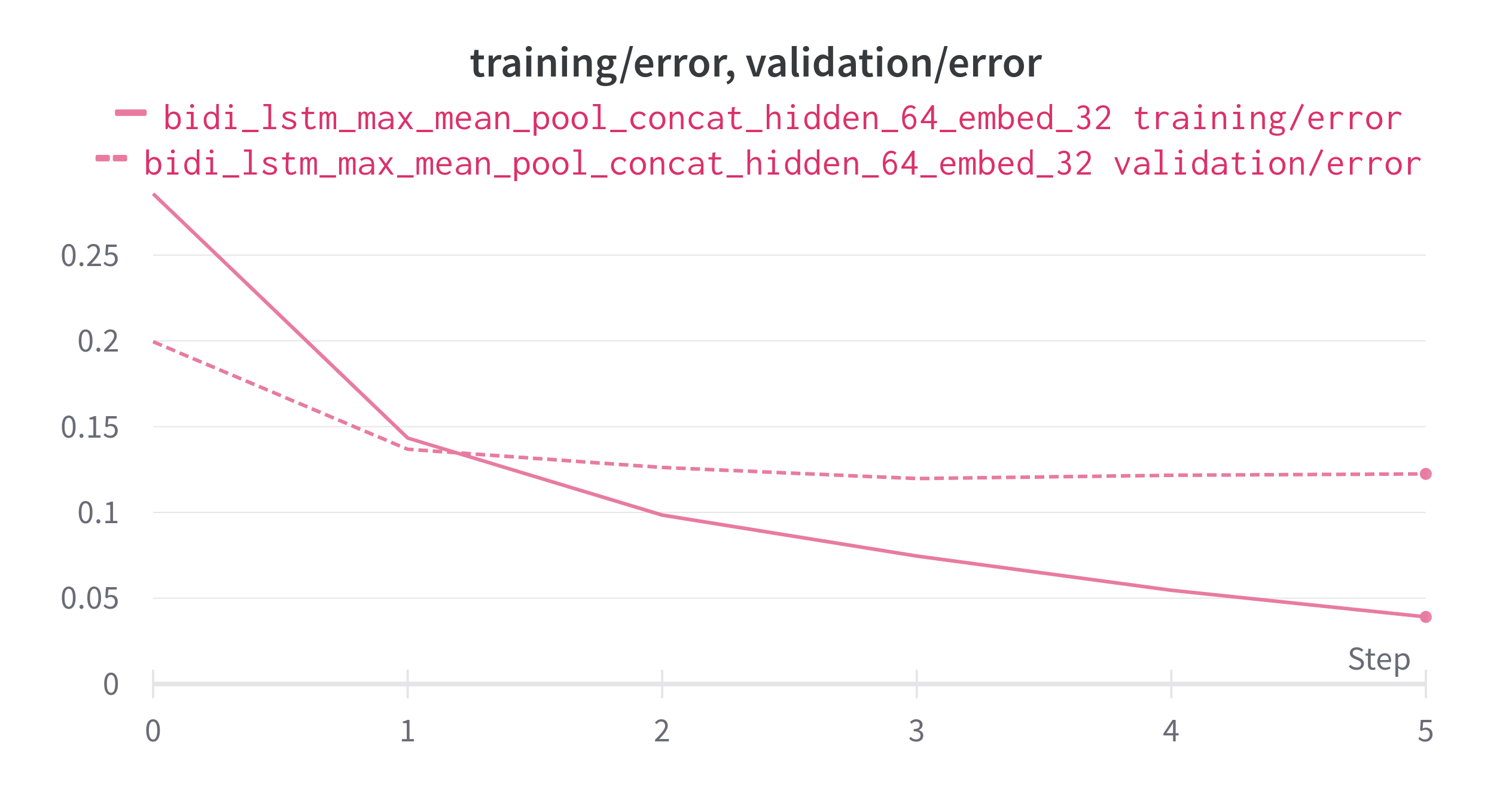
training_accuracy is 94.5%. validation loss is 89.5%.*
*training loss is 0.05 validation loss is 0.12
Model has overfitted, To get the even better performance. follow steps and try.
- Add regularization.
- Add early stopping.
- Reduce features.
- Decrease model size.
- Modify input features from error analysis.
- modify model architecture.
- More data for training.
Using pre-trained embeddings.
In this project, I have trained all the words with help of gensim(library) to get the word embedding/word vectors.
Model architecture
There is tinny change in this model architecture, instead of randomly intialized embeddings, we will use pre-trained embedding to train our model. 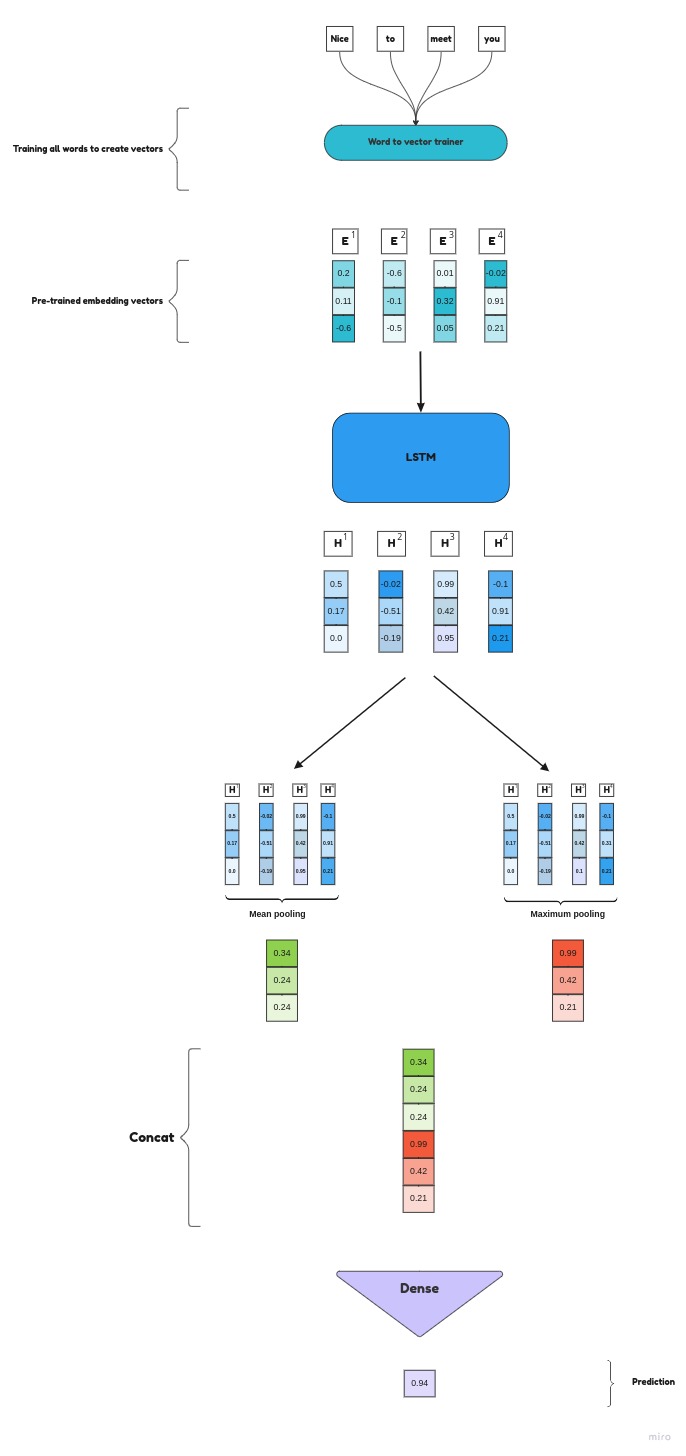
Will see the result after using pre-trained embeddings.
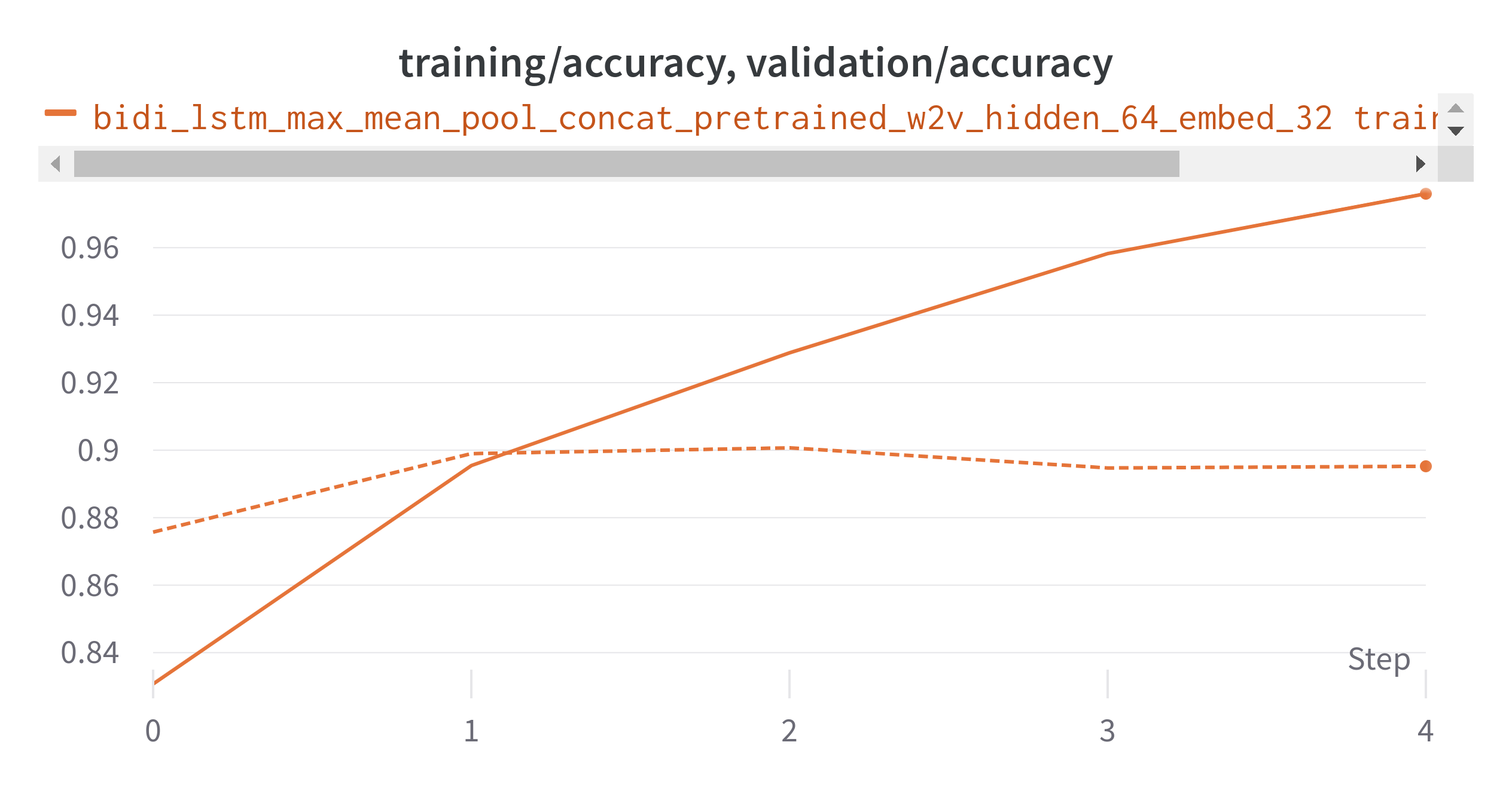
Accuracy
Loss
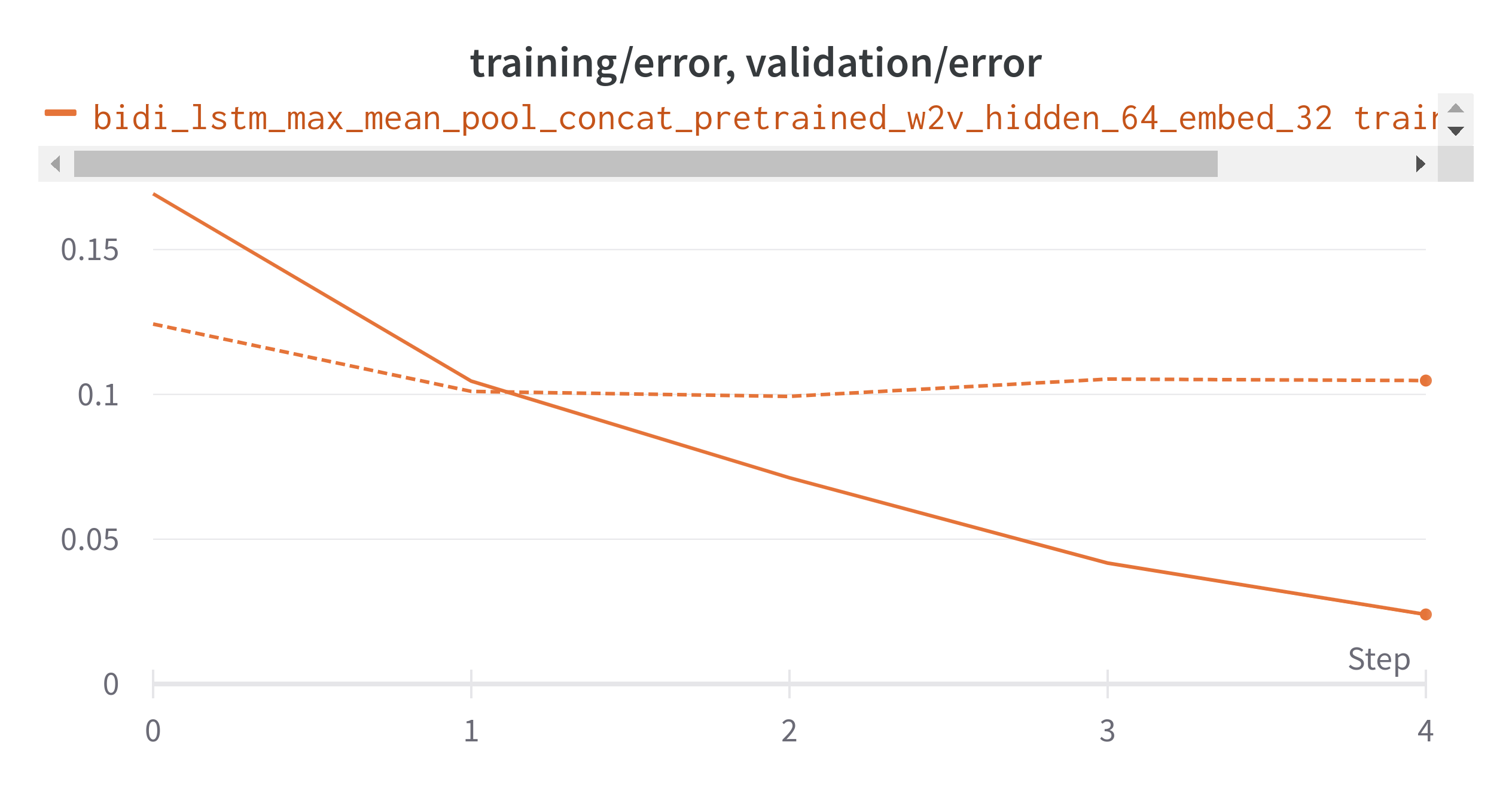
training_accuracy is 97.89%. validation accuracy is 89.7%.*
*training loss is 0.11 validation loss is 0.33
If we observe the result. using pre-tranined embeddings result is performed bit better. but model is overloaded. you can follow above step to optimize the results.
Representing(TSNE) word embeddings.
Each cluster will be regarded as a topic
 Here “editing” word, nearest/similar words are camera,shot,clip. In this image,It is representing the nearest words.
Here “editing” word, nearest/similar words are camera,shot,clip. In this image,It is representing the nearest words. 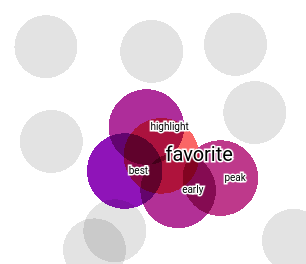
Checking word for “favorite”, nearest words are best,early,highlight, and peak. 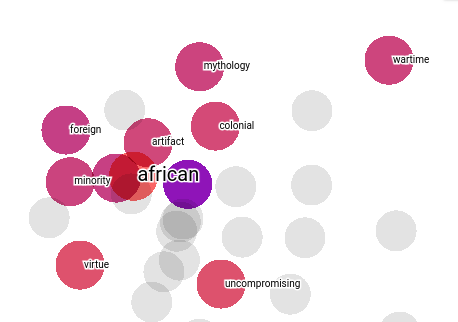
Characters name cluster 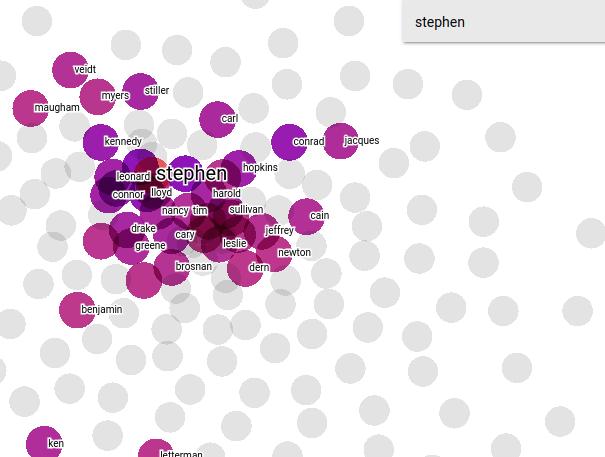
Summary
We have explored dataset and taken several action and observation.
- Removed duplicates.
- Observed 2 classes evenly distributed.
- Decided minimum and maximun review length.
- Trimed sentence to maximun length.
Source Code : Github
If you appreciate the content, Feel free to share the blogs.
Thank you for your time 🌟 .