Convolution for NLP Task
Understanding 1D Convolution Neural Network & Verify.
The blog explains about how 1D-Convolution Neural Network is used for Natural language processing problems, and how the inner calculation wil be happing.
Let’s take a sentence as an example

Parameters :
- in_channels = 5
- out_channels = 2
- kernel_size = 3
- Lin = 10
- stride = 1
- padding = 0
- dilation = 1
One way to understand a convolution operation is to imagine placing convolution filter to input data of same length and width, multiplying the input data of to filter weights correspondingly, which we call it convolution features or input feature maps.
Let’s see how sliding happens to 1D data.
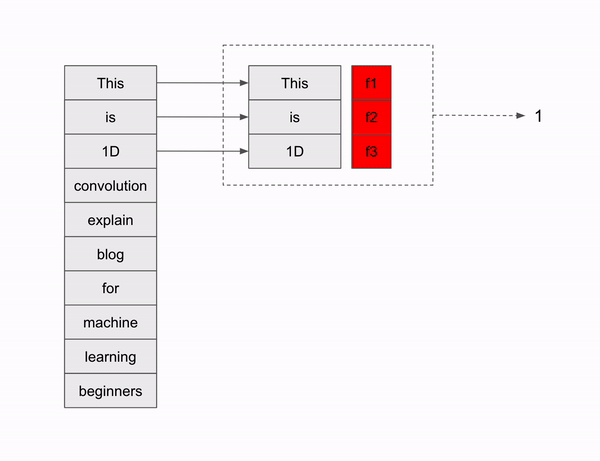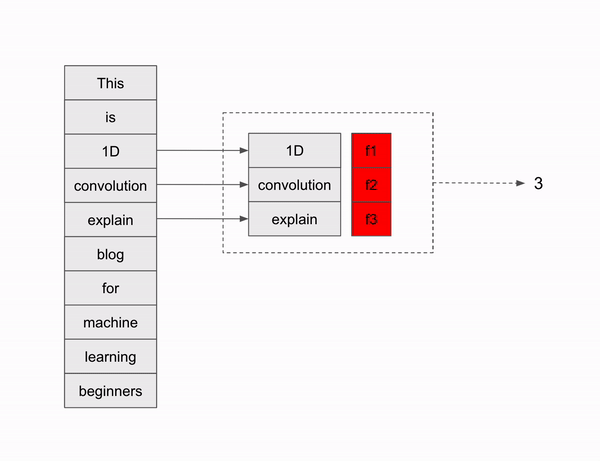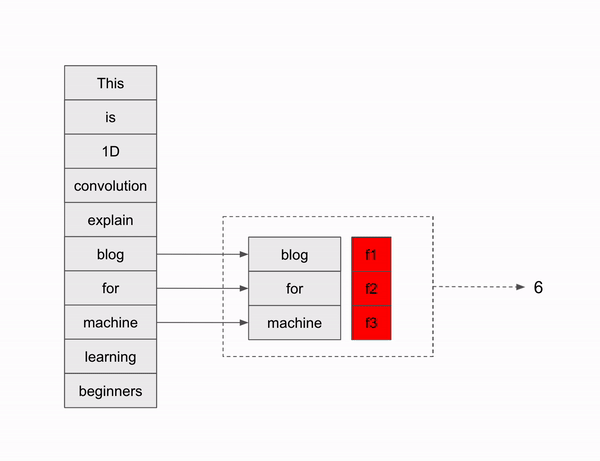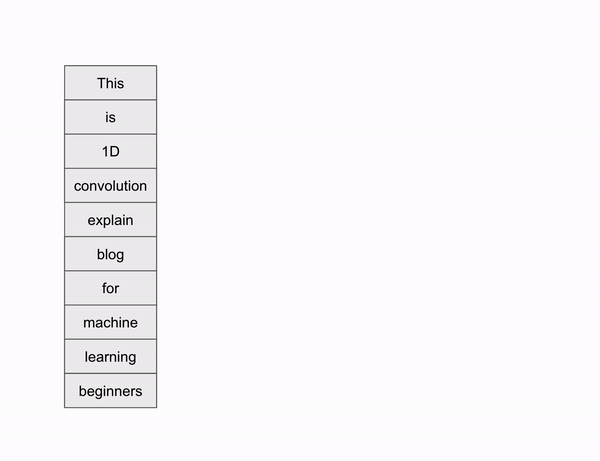
Sliding window happens based on the filter size, which is 3 in our case, So first 3 words are choosen in the beginning, since the stride is one, there will be only one shift, So second word and its consecutive two words are choosen making the second slide window. similarly it follows for next word till the last word is reached. Since there is no padding, sliding window will stop at the last but two words, that is according to the below formula, we get to stop at 8th word of words. In our case, till the word “machine”.

We use first window from now onwards for our furture explanation.
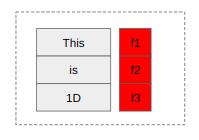
Let’s see how we can use learnable weights to get the desired output from our choosen window input.
Usually process is, converting given words to tokens and initiaing random embedding vector for each word tokens. as we go on traning and upding embedding vectors we get better represented vector at higher dimentions.
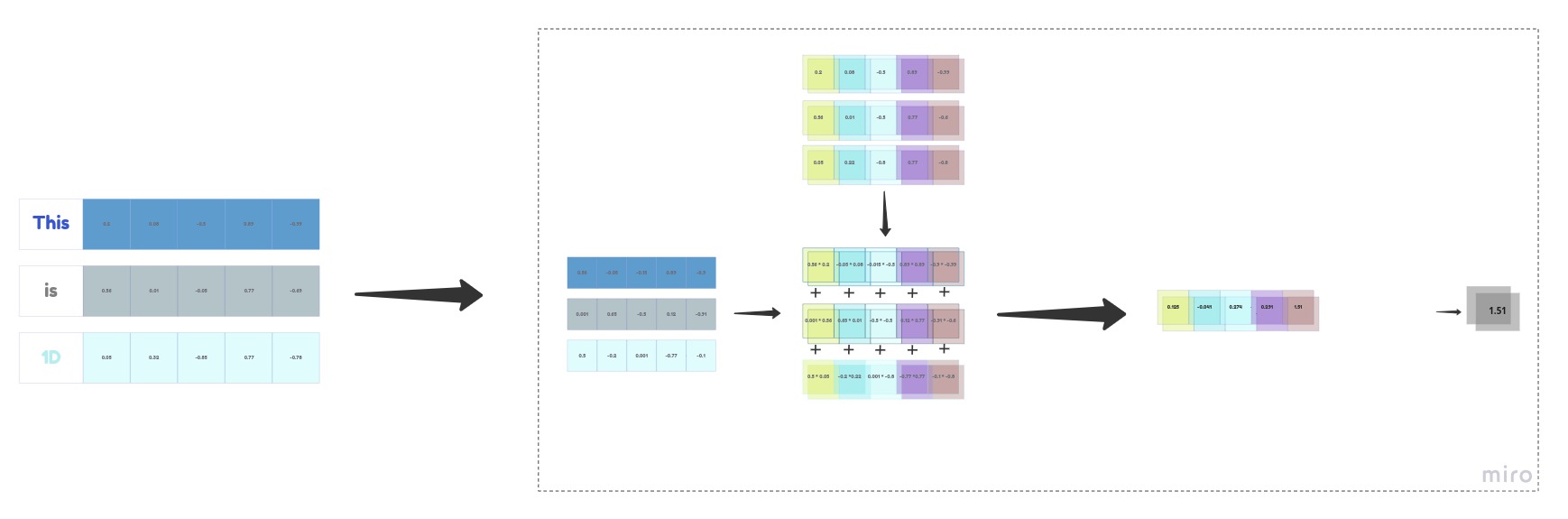
Now we have embedding vectors randomly generated, with shape of (3,5), which is our input,as shown in the image, our transformation of input embeddings to output vector into two (out_channel). This transformation is possible, When we take two initiallyy randomlized weight matrix of shape (2,3,5), each weight matrix are elementwise multipied and summed to same input. we get two values from the transformation.
The below given formula is used for the transformation that we have done for a window.
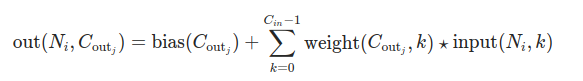
If we observe, we have given input of shape (3,5) and we got output shape (2,1), This is for a first window that we have taken in the beginning. If we do the same transformation to all of our 8 windows we get an output of size (8,2). The same weight matrix (2,3,5) is used for all the 8 windows for transformation, The weight matrix can be called as total kernel weight matrix.
The given below figure will give the sense of understanding for all windows of sample we have taken.
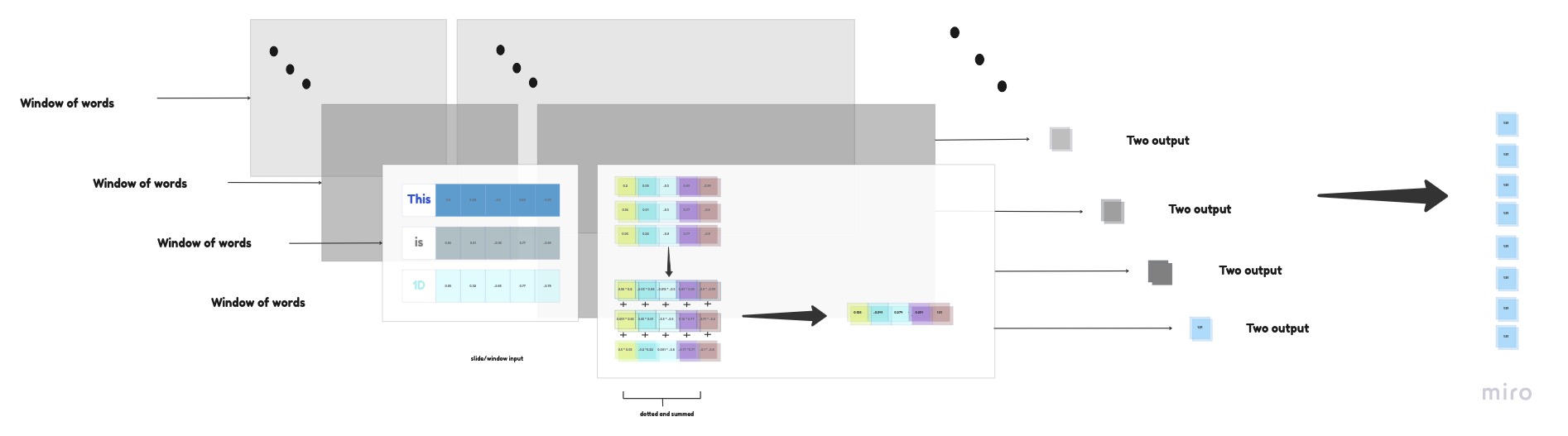
Note : When we were taking input data for a single window, we have taken as (three words,embedding size), Hence, We have weight matrix of shape (2,3,5). In most of the deep learning frameworks it is not the case, They consider (embedding_size,three words). Hense they have transposed weight matrix. Mathematical operation are same, There will be no warry in the output.
We were able to understand, how 1D convolution is applied for a textual data with an embedding size of 5. To verify these above operation are giving correct output, we have used pytorch nn.Conv1d to compare our result, we got exact output.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import torch
from torch import nn
#### VERIFY CONV-1D WITH OUR METHODS ######
c_in = 5
c_out = 2
l = 10
f = 3
bs = 1
with torch.no_grad():
inp = torch.randn(1,c_in,l)
con = nn.Conv1d(c_in,c_out,f,bias=False)
out = con(inp) ##base out
print(out)
inp_d = inp.repeat(c_out,1,1).unsqueeze(0)
all_windows = []
for i in range(0,l):#0,1,2,3--10
print(i,i+f)#7,10
window = inp_d[:,:,:,i:i+f]
res =(window*con.weight.unsqueeze(0)).sum(dim=(-1,-2),keepdim=True).squeeze(-1)
all_windows.append(res) #b,2
if i+f==l:
break
results = torch.concat(all_windows,dim=-1)
print(results)
print((out.half()==results.half()).all().item())
print()
Implementing 1D-CNN using IMDb dataset.
Previously, I have used LSTM to classify movie reviews, In this article, I will be using 1D Convolution Neural Network. and comparing the results between LSTM & 1D CNN.
In this blog, We have preprocessed data, Let’s use the same preprocessed data to implement using 1D-CNN.
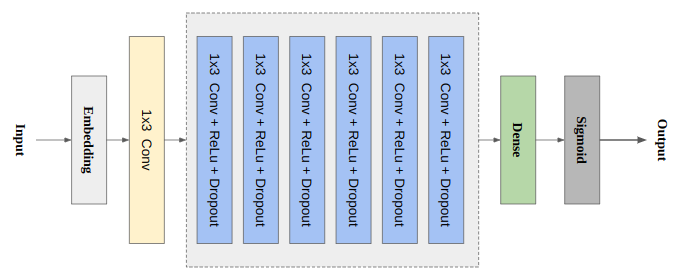
How our model architecture look,
We get embeddings from embedding layer, we pass them through several 1D convolution networks along with Dropout and Relu.
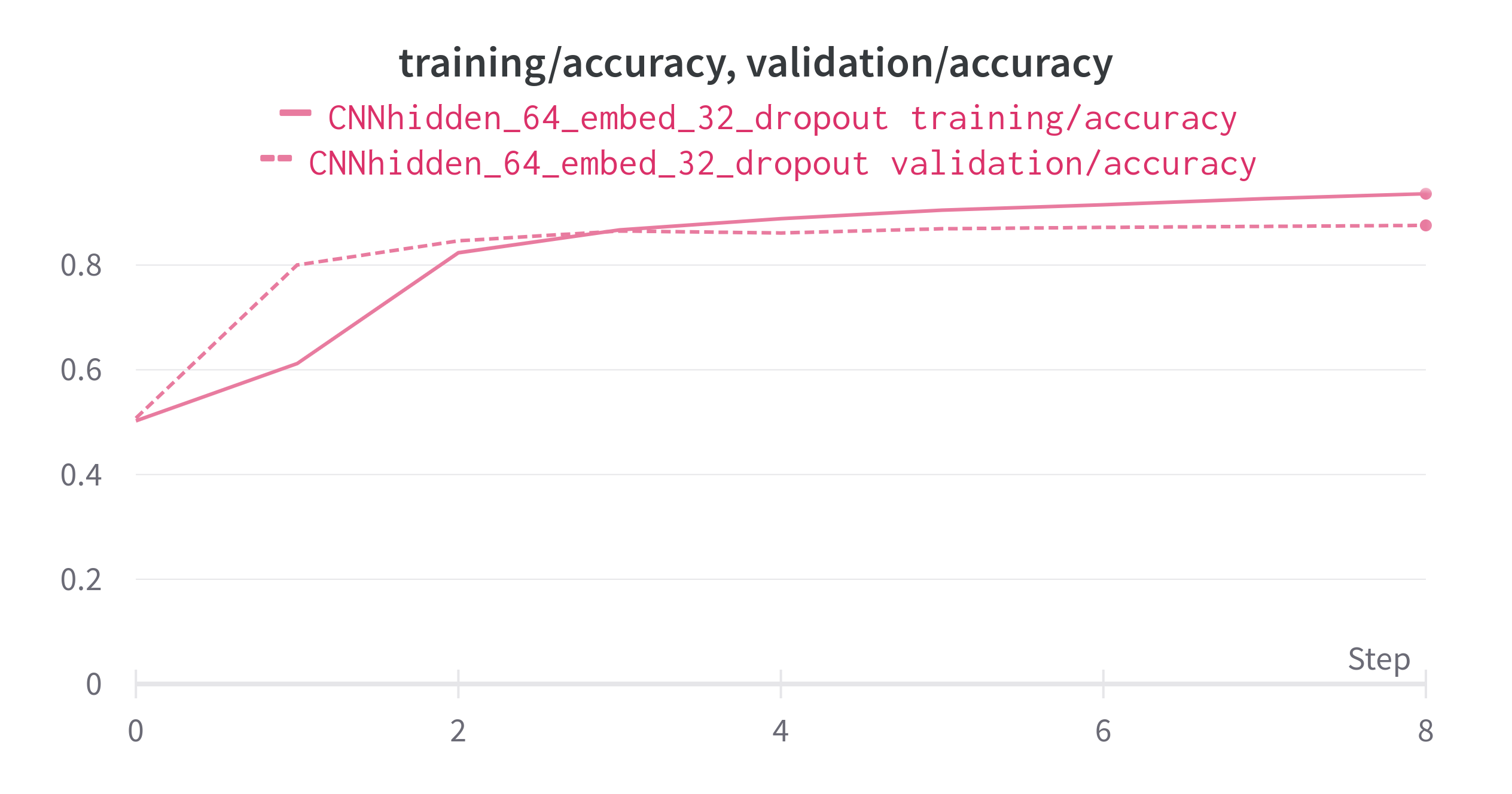
When we train it for 8 epoch, we got an training accuracy of 93.6, validation accuracy of 87.5.
Accuracy
Loss
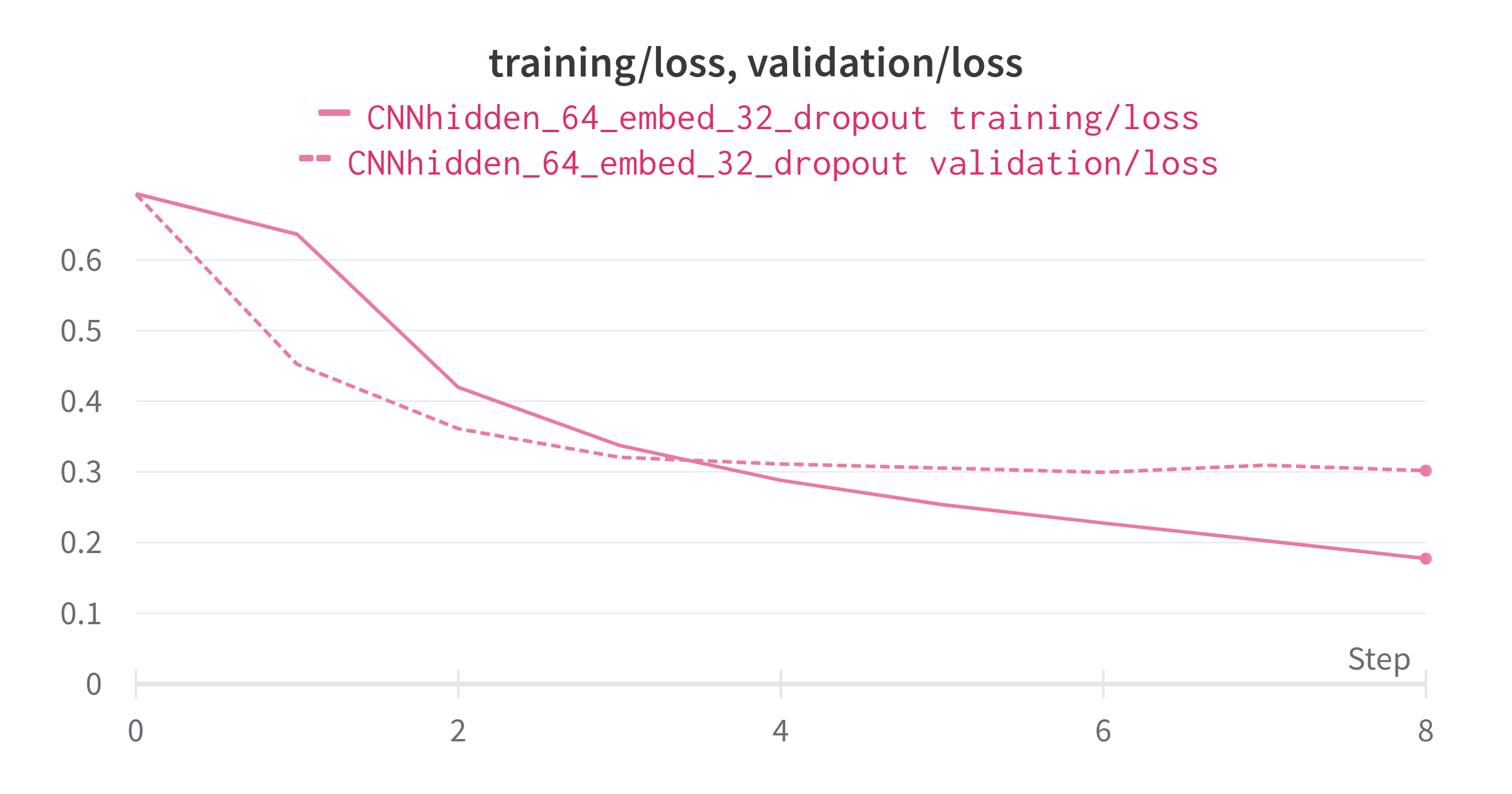
from the above plot we can see that model has less overfitted. and alos the performace is less compare to LSTM.

When we compare the model LSTM and 1D CNN, We got better performance in LSTM model.
Summary :
We have understood, How 1D Convolution Neural Network can be used in text data and we also have gone through how weights and inputs are multiplied and summed visually.
We have verified using deep learning frameworks, the transformations happening inside CNN are same as what we have understood, taken steps and seen visually in this article.
Source Code : Github
If you appreciate the content, Feel free to share the blogs.
Thank you for your time.