Multi Label Classification Using PyTorch TransformerEncoderLayer
In previous blog we used pretrained BERT-base-uncased model for text classification, Which was 99% accurate.
In this blogs, let us use nn.TransformerEncoder to classify the results, and mean pooling the output represenation of the transformer.
We have used nn.Embedding on top of transformer layer and sequences are encoded and passed to transformer. We get hidden representation from transformer. Then we mean at the sequence level to get representation of our model size 512, then we convert and classify the labels.
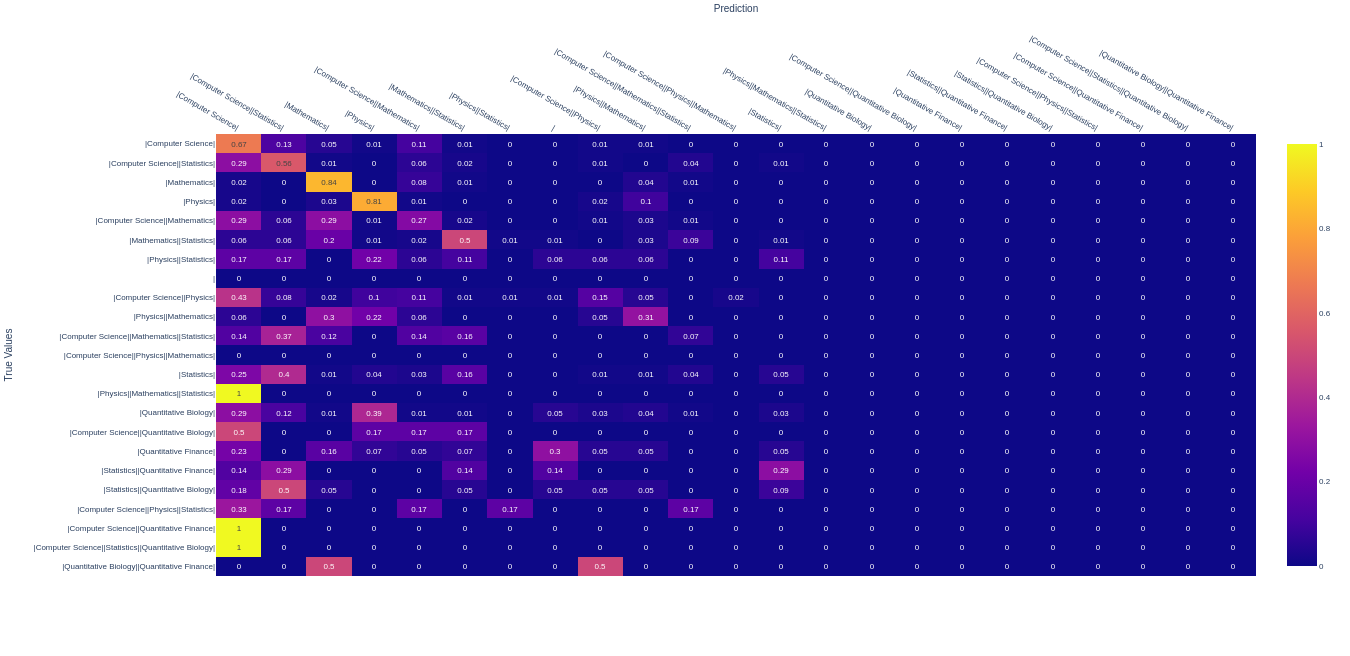
Plotting confustion matrix would give us better way of understanding where the model is making classification problem.
There are many other ways to plot confusion matrix for multi-label classification but, The unique way of understanding of multi-label in confustion matrix is converting them into multi-classes them plot it.
From the above plot, take an example. The most of time model has predicted Mathematics,Physics and Computer Science correctly. In some cases, While it has to be predict Statistics, It is predicted Mathematics.
Model is getting confused between Statistics and Mathematics.
See the label distribution.
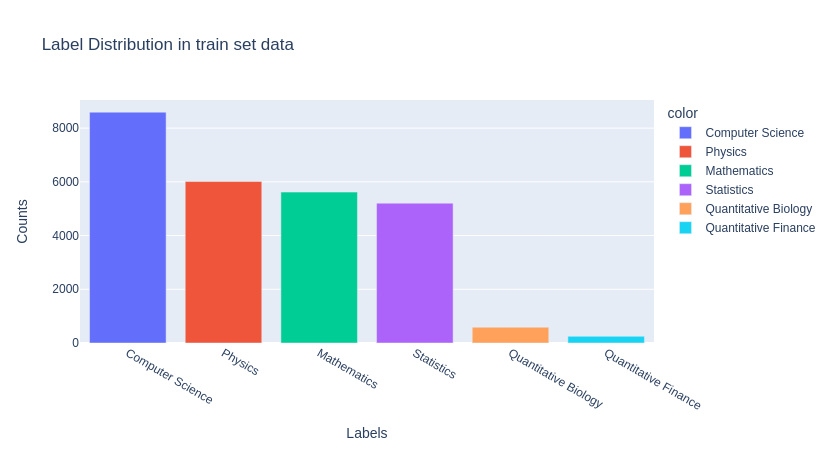
Dataset is imbalance, “Quantitative Biology” and “Quantitative Finance” labels are very less compared to other labels. This also would be the problem.
How we can overcome this kind of problems.
There are several ways to solve such problem like,
- Oversampling : Upsample minority classes.
- Undersampling : Downsample the majority classes.
Synthetic Minority Oversampling Technique : Oversamples minority class adding duplicate records of minority class.
- Few more…
The simple way is use the pos_weight in the nn.BCEWithLogitsLoss.
pos_weight : recommends the pos_weight to be a ratio between the negative counts and the positive counts for each class.
So, if len(dataset) is 1000, element 0 of your multihot encoding has 100 positive counts, then element 0 of the pos_weights_vector should be 900/100 = 9. That means that the binary crossent loss will behave as if the dataset contains 900 positive examples instead of 100.
\[\text{pos_weight} = \frac{\sum (y == 0)}{\sum y}\]This would solve the problem of imbalance dataset.
Let’s train the model with pos_weights to balance dataset
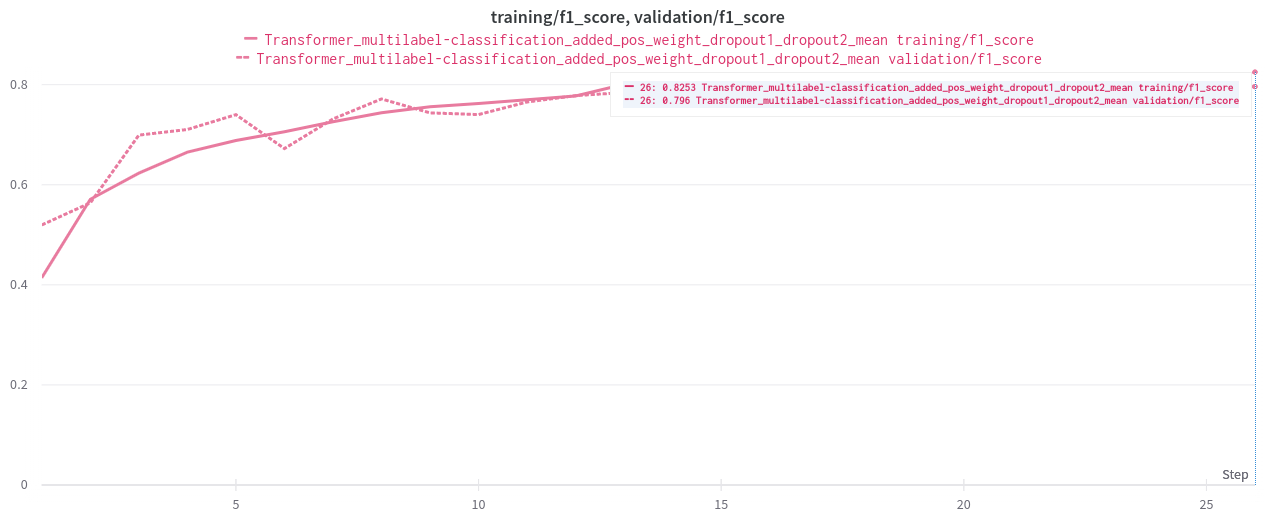
Model has not performed good, f1-score for validation data is 79%.
What would be the reason? Might be you have to try using other methods to solve the imbalance dataset problem.
Try It Yourself : Agumenting the sequences. Suppose for label “Quantitative Biology”, You have a abstract with 5 sentence, you can trim the each sentence and label it as “Quantitative Biology” label. This Upsample minority classes.
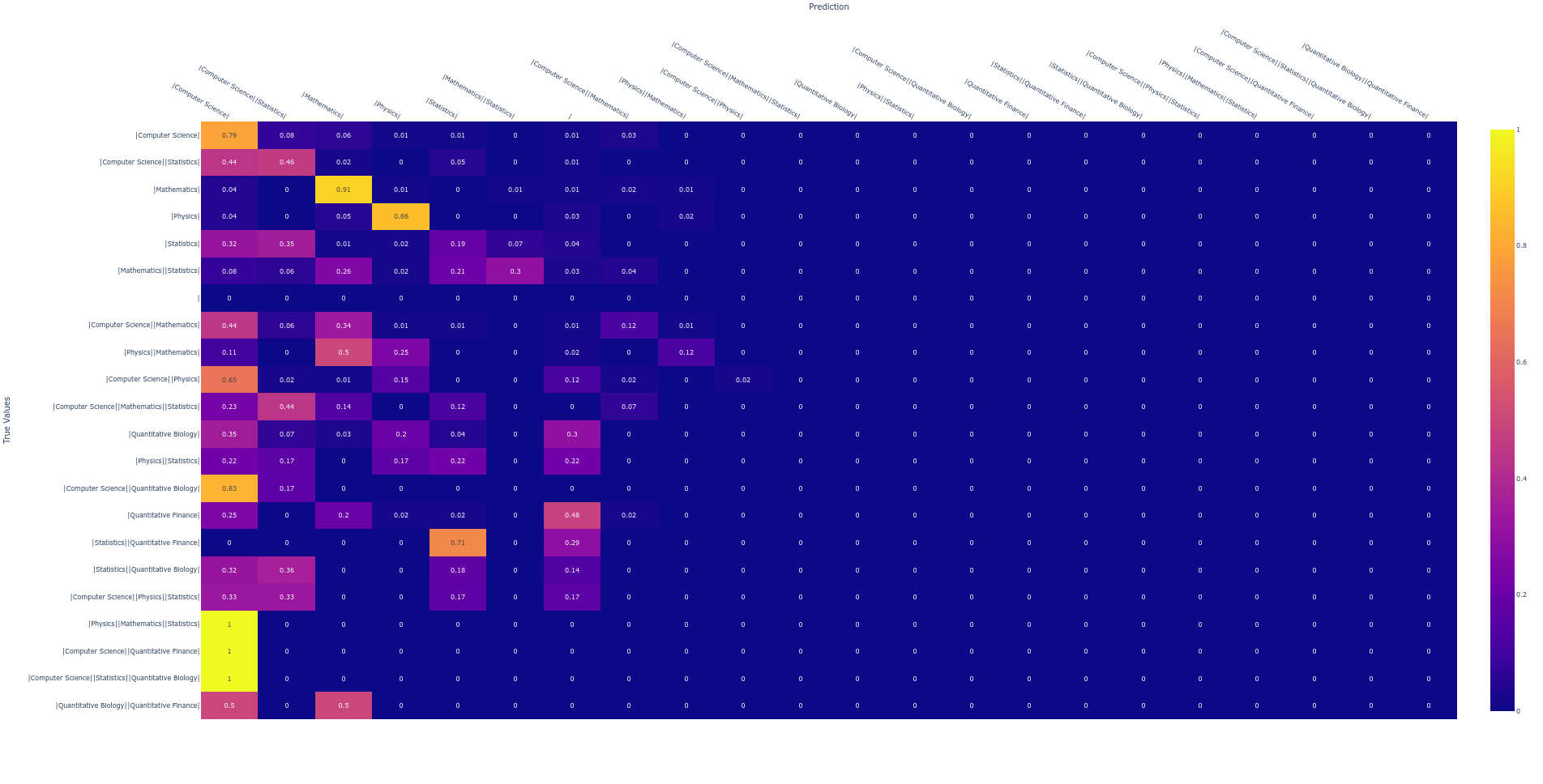
I have trained model using pos_weight method. let’s see the result.
If you observe a true label “Physics,Mathematics,Statistics”, all the time it has predicted only “Computer Science”, Where it is suppose to predict “Physics,Mathematics and Statistics”.
If you look into the confusion matrix, You find right/wrong predictions and also you will get to know, In which labels the model is making mistake to classify the text.
Implemented source code is here : GitHub
Reference :