Concepts You should know before Getting into Transformer

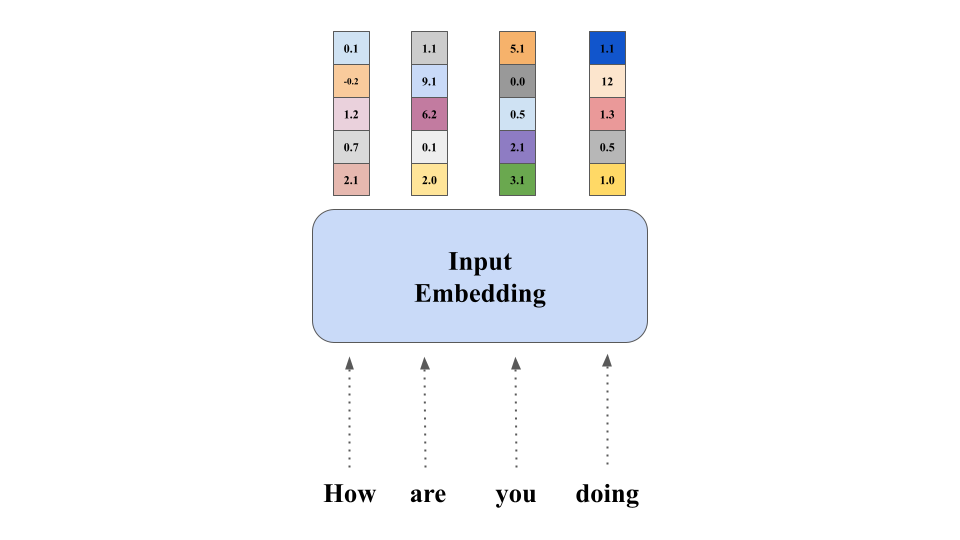
1. Input Embedding
Neural network learn through numbers, so each words will be mapped to vectors to represent particular word. Embedding layer can be thought of as a lookup table that stores word embeddings and retrieve them using indices.
Words that have same meaning will be close in terms of euclidian distance/cosine similarity. for example, in the below word represenation, “saturday”,”sunday”,”monday” are associated with same concept, so we can see that the words are resulting similar.

2. Positional Encoding
The determining the position of the word, Why do we need to determine the position of word? because, the transformer encoder has no recurrence like recurrent neural networks,we must add some information about the positions into the input embeddings. This is done using positional encoding. The authors of the paper used the following functions to model the position of a word.
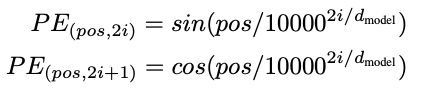
We will try to explain positional Encoding.
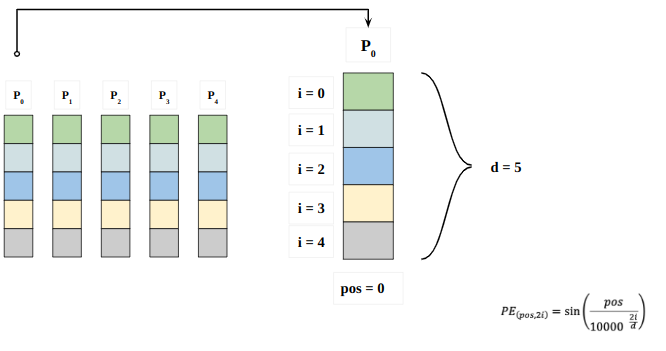
Here “pos” refers to the position of the “word” in the sequence. P0 refers to the position embedding of the first word; “d” means the size of the word/token embedding. In this example d=5. Finally, “i” refers to each of the 5 individual dimensions of the embedding (i.e. 0, 1,2,3,4)
if “i” vary in the equation above, you will get a bunch of curves with varying frequencies. Reading off the position embedding values against different frequencies, giving different values at different embedding dimensions for P0 and P4.
3. Scaled Dot-Product Attention
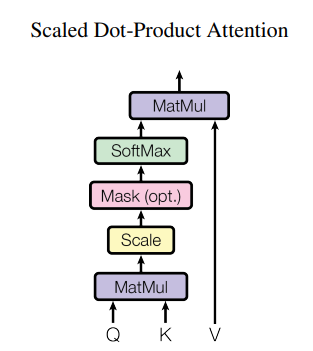
In this query Q represents a vector word, the keys K which are all other words in the sentence, and value V represents the vector of word.
The purpose of attention is to calculate the importance of the keys term compared to the query term related to the same person/things or concept.
In our case, V is equal to Q.
The attention mechanism gives us the importance of the word in a sentence.
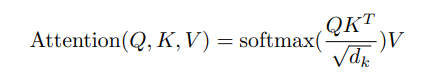
When we compute the normalized dot product between the query and the keys, we get a tensor that represents the relative importance of each other word for the query.
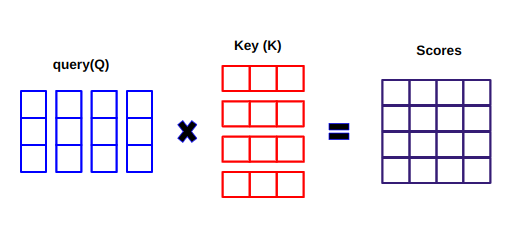
When computing the dot product between Q and K.T, we try to estimate how the vectors (i.e words between query and keys) are aligned and return a weight for each word in the sentence.
Then, we normalize the result squared of d_k and The softmax function regularizes the terms and rescales them between 0 and 1.
Finally, we multiply the result( i.e weights) by the value (i.e all words) to reduce the importance of non-relevant words and focus only on the most important words.
4. Residual Connections
The multi-headed attention output vector is added to the original positional input embedding. This is called a residual connection/skip connection. The output of the residual connection goes through a layer normalization. The normalized residual output is passed through a pointwise feed-forward network for further processing.
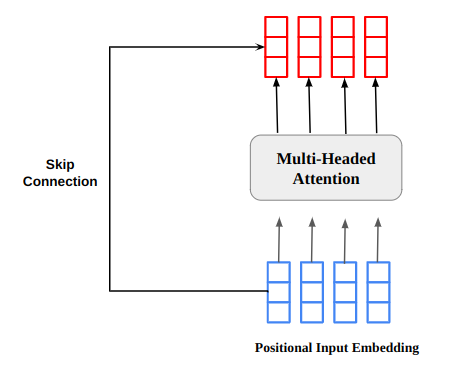
5. Mask
The mask is a matrix that’s the same size as the attention scores filled with values of 0’s and negative infinities.
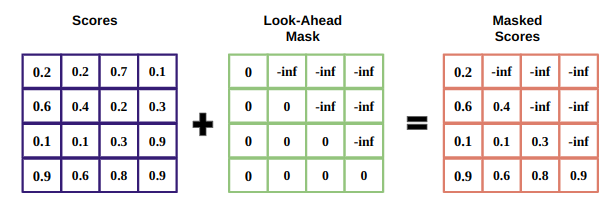
The reason for the mask is because once you take the softmax of the masked scores, the negative infinities get zero, leaving zero attention scores for future tokens.
This tells the model to put no focus on those words.
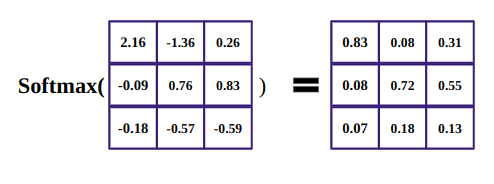
6. Softmax function
The purpose of softmax function is to grab real numbers(positive and negative) and turn them into positive numbers which sum to 1.