Understanding Linear Regression in Supervised Learning
![]()
Introduction
Machine learning : Learn from data and improve decision-making over time without human interference.
Types of Learning In Machine Learning
There are two different types of learning’s in machine learning.
- Supervised : Learn from the labeled data.
- Unsupervised : Learn from the unlabeled data.
In this blog, You will understand about Supervised Learning.
There are two sub-categories in the Supervised Learning:
- Regression
- Classification
Regression : That is used to predict continuous values, such as house prices, stock prices.
To better understand, one might try out the house price prediction and linear regression model.
Understanding Linear Regression
Linear Regression Model : Fitting straight line to the data.
Let’s start with a problem that you can address using linear regression. Say you want to predict the price of a house based on the size of the house.
Here we have a graph where the horizontal axis is the size of the house in square feet, and the vertical axis is the price of a house in thousands of dollars.
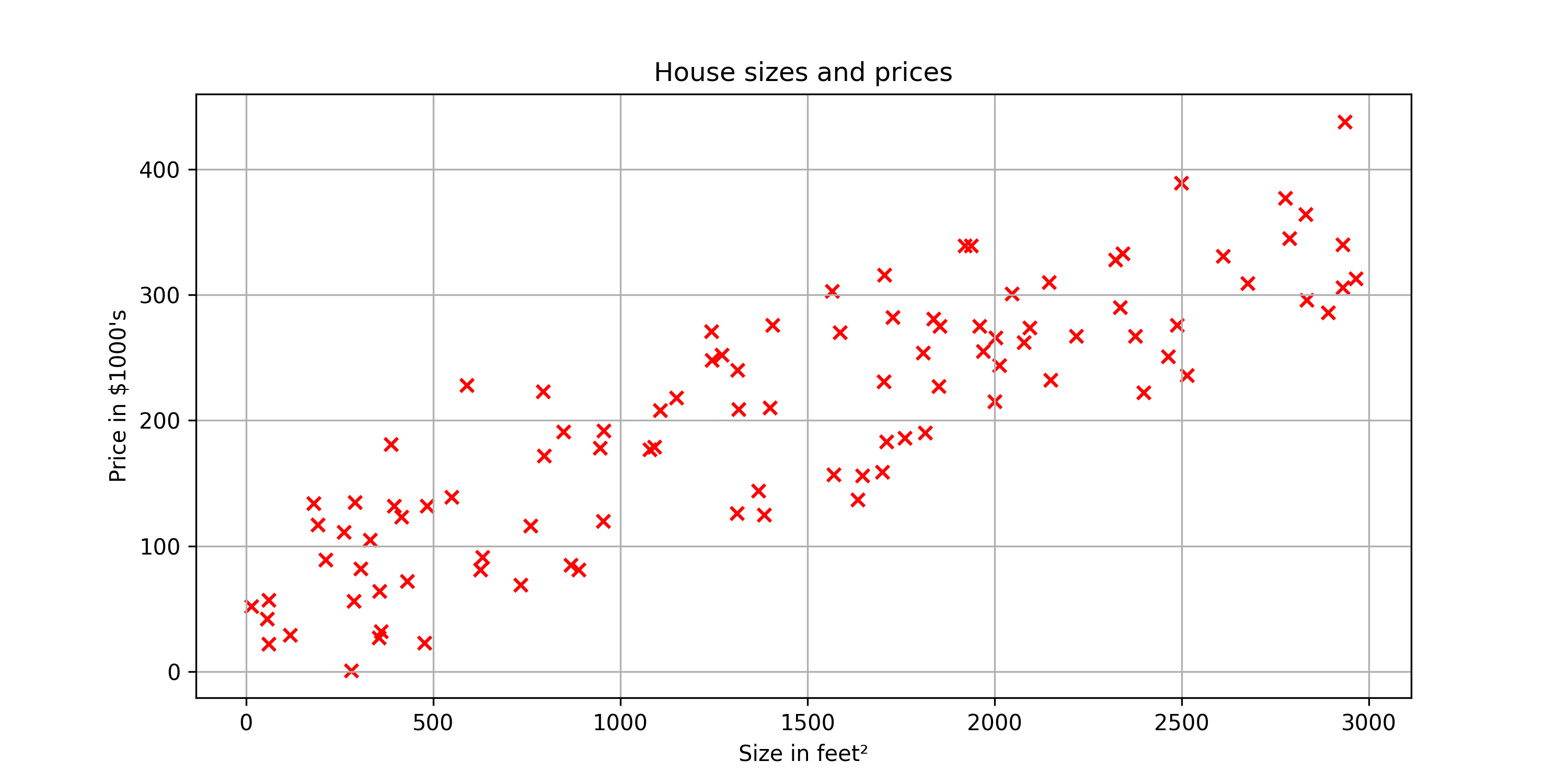
Now, Let’s say you are real estate agent, and you’re helping a client to sell her house. She is asking you, how much do you think I can get for this house? This dataset might help you estimate the price she could get for it by the help of linear regression model from this dataset.
Your model will fit a straight line to the data, which might look like this.
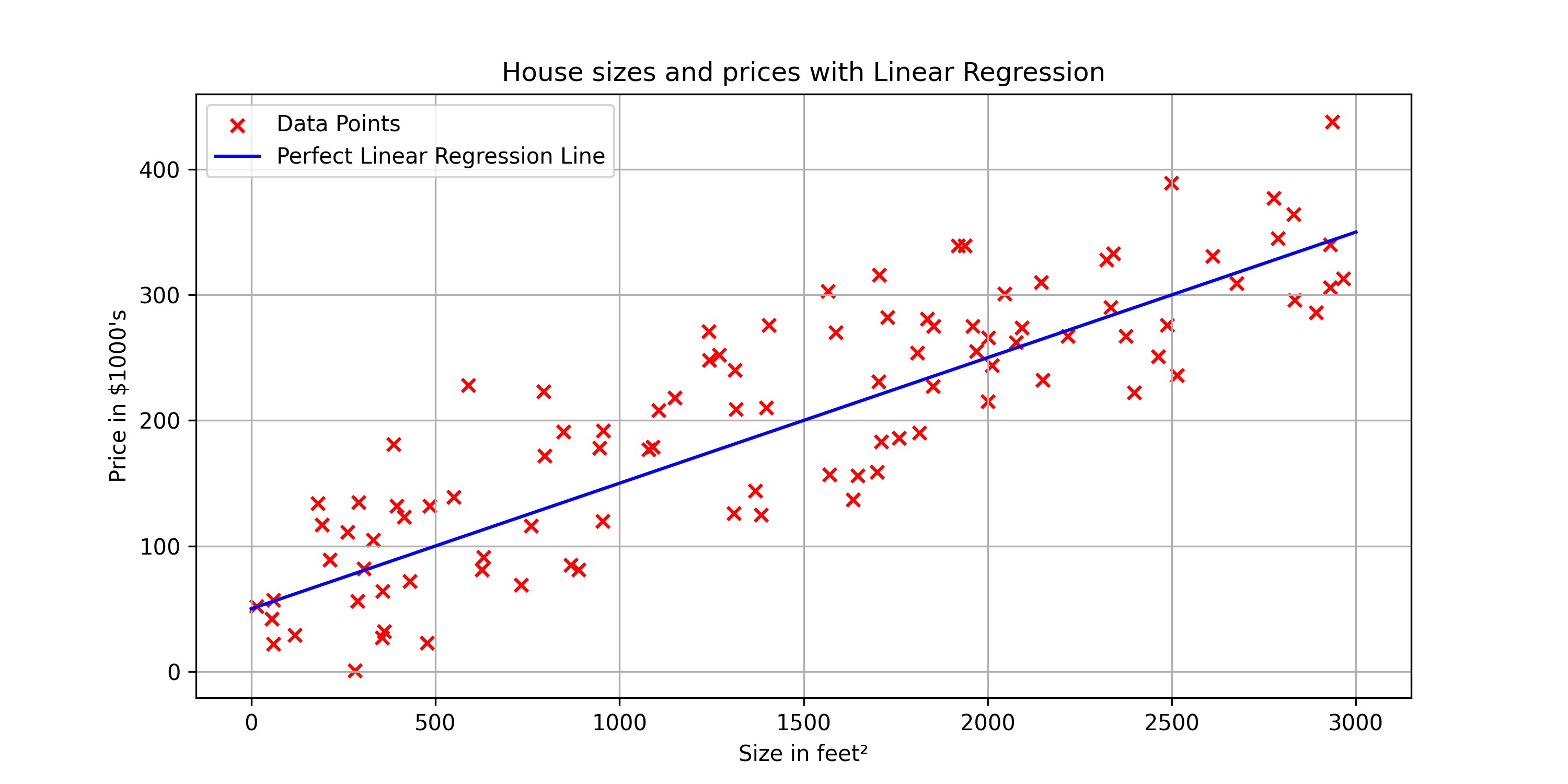
Based on this straight line fit to the data,
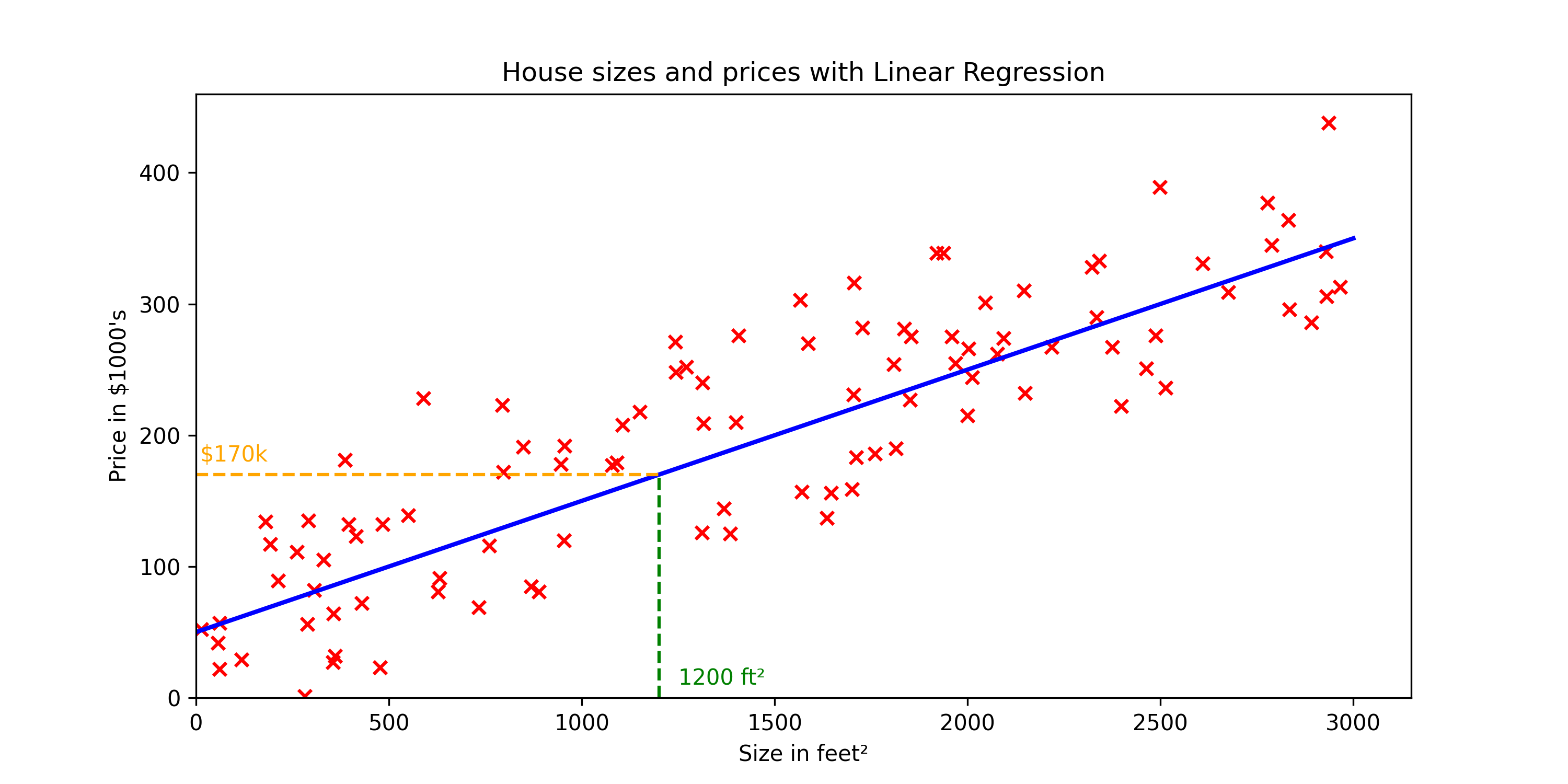
you can see that the house is 1200 square feet, it will intersect the best fit line over here, and if you trace that to the vertical axis on the left, you can see the price is maybe around here, say about $170,000.
This is an example of what’s called a supervised learning model. We call this supervised learning because you are first training a model by giving a data that has right answers because you get the model examples of houses with both the size of the house, as well as the price that the model should predict for each house.
Here’s a corrected version of the quoted sentence:
“When the linear line does not fit correctly, it can lead to increases and decreases in the predicted prices.”
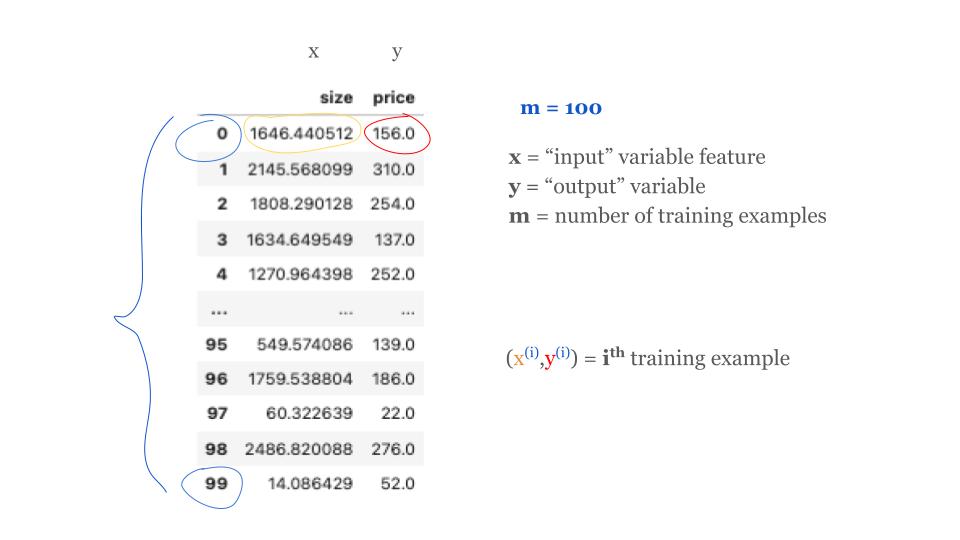
Now we have understood, what a traning dataset is like. Let look at the process of how supervised learning works.
Process of How Supervised Learning Works
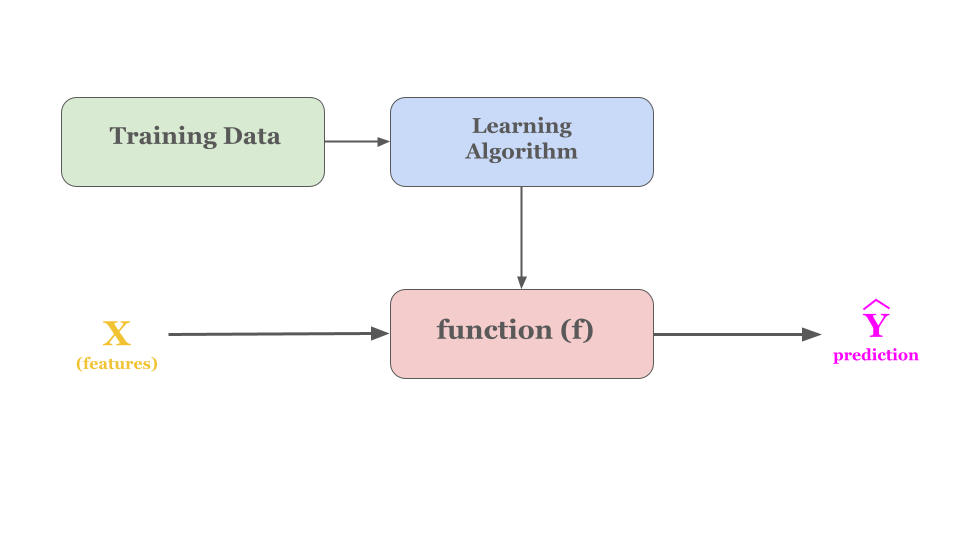
How to represent f?
Certainly! Here’s a more conceptual take:
“In the equation \(f(x) = wx + b\), think of \(x\) as your input. The function transforms this input using fixed values for \(w\) and \(b\) to produce the output, \(\hat{y}\), which is your estimated result.”
In this equation, all you need to do is find the right \(w\) and \(b\) that make \(\hat{y}\) predict correctly for your dataset.
We can try to find the right \(w\) and \(b\) with help of cost function.
Explore how adjustments to the weights (\(w\)) and bias (\(b\)) affect the predictions by using the interactive linear regression model below.
Interactive Linear Regression
Cost Function
Cost function will tell us how well the model is doing so that we can try to get it to do better.
let’s first take a look at how to measure how well a line fits the training data. To do that, we’re going to construct a cost function. The cost function takes the prediction \(\hat{y}\) and compares it to the target \(y\) by taking \(\hat{y}\) minus \(y\).
\[\begin{equation} \text{Error} = (\hat{y} - y) \end{equation}\]This difference is called the error, we’re measuring how far off to prediction is from the target. Next, let’s computes the square of this error. Also, we’re going to want to compute this term for different training examples i in the training set.
When measuring the error, for example \(i\), we’ll compute this squared error term. Finally, we want to measure the error across the entire training set. In particular, let’s sum up the squared errors like this. We’ll sum from \(i\) equals 1,2, 3 all the way up to \(m\). Remember, \(m\) is the number of training examples, which is 100 for this dataset.
To build a cost function that doesn’t automatically get bigger as the training set size gets larger by convention, we will compute the average squared error instead of the total squared error and we do that by dividing by m or 2m like this,
\[J(w,b) = \frac{1}{m} \sum_{i=0}^{m-1} (f_{w,b}(x^{(i)}) - y^{(i)})^2\] \[\text{or}\] \[J(w,b) = \frac{1}{2m} \sum_{i=0}^{m-1} (f_{w,b}(x^{(i)}) - y^{(i)})^2\]This is also squared error cost function.
In machine learning different people will use different cost functions for different applications, but the squared error cost function is the most commonly used for linear regression and for that matter, all regression problems where seems to give good results for many applications.
The goal of the linear regression is to minimize the cost function \(J(w,b)\) we do it with help of gradient descent algorithm.
\[[minimize \quad J(w, b)]\]Gradient Descent
Gradient descent is used all over the place in machine learning, not just for linear regression. Here’s an overview of what we’ll do with gradient descent. You have the cost function \(j\) of \(w\), \(b\) that you want to minimize.
Algorithm:
- Start with some \(w\), \(b\)
- Keep changing \(w\) and \(b\) to reduce \(J(w,b)\)
- Untill we settle at or near minima.
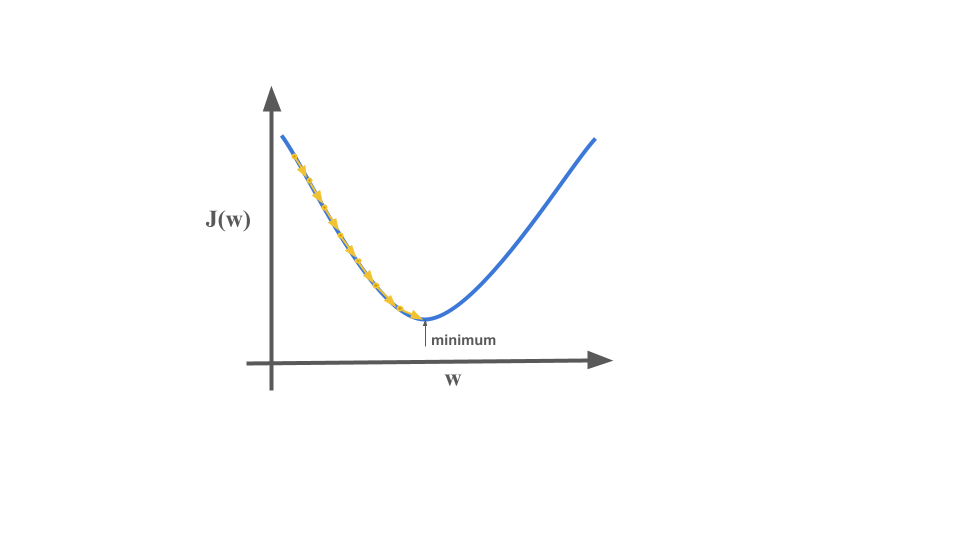
Gradient Descent Algorithm
Gradient descent was described as:
\[\begin{align*} \text{repeat until convergence:} \; \{ \newline \; w &= w - \alpha \frac{\partial J(w,b)}{\partial w} \; \newline b &= b - \alpha \frac{\partial J(w,b)}{\partial b} \newline \} \end{align*}\]where, parameters \(w\), \(b\) are updated simultaneously. The gradient is defined as:
\[\begin{align} \frac{\partial J(w,b)}{\partial w} &= \frac{1}{m} \sum_{i = 0}^{m-1} (f_{w,b}(x^{(i)}) - y^{(i)})x^{(i)} \\ \frac{\partial J(w,b)}{\partial b} &= \frac{1}{m} \sum_{i = 0}^{m-1} (f_{w,b}(x^{(i)}) - y^{(i)}) \\ \end{align}\]Here simultaneously means that you calculate the partial derivatives for all the parameters before updating any of the parameters.
“Don’t worry about those equations; they’re just math puzzles. Once you figure them out, you’ll find they’re simpler than tying your shoes!”
Implementation
Let’s build a linear regression model from scratch. You can follow along in the notebook linked below:
# !wget https://raw.githubusercontent.com/ravikumarmn/Introduction-to-Machine-Learning/main/house_price_data.csv
# %pip install numpy pandas matplotlib
import numpy as np
import pandas as pd
import copy
import math
import matplotlib.pyplot as plt
house_price_data = pd.read_csv("house_price_data.csv")
house_price_data.head()
| size | price | |
|---|---|---|
| 0 | 1646.440512 | 156.0 |
| 1 | 2145.568099 | 310.0 |
| 2 | 1808.290128 | 254.0 |
| 3 | 1634.649549 | 137.0 |
| 4 | 1270.964398 | 252.0 |
plt.figure(figsize=(10, 5))
plt.scatter(house_price_data['size'],house_price_data['price'], color='red', marker='x')
plt.title('House sizes and prices')
plt.xlabel('Size in feet²')
plt.ylabel('Price in $1000\'s')
plt.xlim(left=0)
plt.ylim(bottom=0)
plt.legend(["Data Points"], fontsize="x-large")
plt.show()

# Normalize data
size_mean = house_price_data['size'].mean()
size_std = house_price_data['size'].std()
price_mean = house_price_data['price'].mean()
price_std = house_price_data['price'].std()
house_price_data['size_normalized'] = (house_price_data['size'] - size_mean) / size_std
house_price_data['price_normalized'] = (house_price_data['price'] - price_mean) / price_std
x_train = np.array(house_price_data['size_normalized'])
y_train = np.array(house_price_data['price_normalized'])
$$ f_{w,b}(x) = wx + b $$
def linear_fn(x_train, weights, bias):
# f(x) = wx + b
return weights * x_train + bias
In linear regression, you utilize input training data to fit the parameters $w$ and $b$ by minimizing a measure of the error between our predictions $f_{w,b}(x^{(i)})$ and the actual data $y^{(i)}$. The measure is called the cost, $J(w,b)$. In training, you measure the cost over all of our training samples $x^{(i)}, y^{(i)}$:
def compute_cost(x_train, y_train, weights, bias):
m = x_train.shape[0]
f_wb = linear_fn(x_train,weights,bias)
cost = np.sum((f_wb - y_train)**2)
total_cost = (1 / (2 * m)) * cost
return total_cost
# compute_cost(x_train, y_train, 1, 1)
Gradient descent was described as:
$$ \begin{align*} \text{repeat until convergence:} \; \{ \newline \; w &= w - \alpha \frac{\partial J(w,b)}{\partial w} \tag{3} \; \newline b &= b - \alpha \frac{\partial J(w,b)}{\partial b} \newline \} \end{align*} $$
where, parameters $w$, $b$ are updated simultaneously. The gradient is defined as:
$$ \begin{align} \frac{\partial J(w,b)}{\partial w} &= \frac{1}{m} \sum_{i = 0}^{m-1} (f_{w,b}(x^{(i)}) - y^{(i)})x^{(i)} \tag{4}\\ \frac{\partial J(w,b)}{\partial b} &= \frac{1}{m} \sum_{i = 0}^{m-1} (f_{w,b}(x^{(i)}) - y^{(i)}) \tag{5}\\ \end{align} $$
Here simultaneously means that you calculate the partial derivatives for all the parameters before updating any of the parameters.
def compute_gradient(x_train, y_train, weights, bias):
m = x_train.shape[0]
f_wb = linear_fn(x_train, weights, bias)
error = f_wb - y_train
dj_dw = np.dot(error, x_train)/m # We use the dot product, which inherently includes the sum of the element-wise products.
dj_db = np.sum(error) / m # sum the error terms.
return dj_dw, dj_db
# compute_gradient(x_train, y_train, 1, 1) # (-646.0, -397.5)
def gradient_descent(x_train, y_train, w_init=0, b_init=0, alpha = 0.001, num_iters=10000):
w = copy.deepcopy(w_init)
b = b_init
w = w_init
J_history = list()
p_history = list()
for i in range(num_iters):
dj_dw, dj_db = compute_gradient(x_train, y_train, w, b)
b = b - alpha * dj_db
w = w - alpha * dj_dw
if i<100000: # prevent resource exhaustion
J_history.append(compute_cost(x_train, y_train, w , b))
p_history.append([w,b])
if i% math.ceil(num_iters/10) == 0:
print(f"Iteration {i:4}: Cost {J_history[-1]:0.2e} ",
f"dj_dw: {dj_dw: 0.3e}, dj_db: {dj_db: 0.3e} ",
f"w: {w: 0.3e}, b:{b: 0.5e}")
return w, b, J_history, p_history
w_final, b_final, J_hist, p_hist = gradient_descent(x_train ,y_train)
print(f"(w,b) found by gradient descent: ({w_final:8.4f},{b_final:8.4f})")
Iteration 0: Cost 4.94e-01 dj_dw: -8.558e-01, dj_db: 1.554e-17 w: 8.558e-04, b:-1.55431e-20 Iteration 1000: Cost 1.76e-01 dj_dw: -3.178e-01, dj_db: -4.996e-17 w: 5.437e-01, b: 3.49232e-17 Iteration 2000: Cost 1.32e-01 dj_dw: -1.180e-01, dj_db: -3.220e-17 w: 7.453e-01, b: 7.10865e-17 Iteration 3000: Cost 1.26e-01 dj_dw: -4.384e-02, dj_db: -5.773e-17 w: 8.202e-01, b: 1.03145e-16 Iteration 4000: Cost 1.25e-01 dj_dw: -1.628e-02, dj_db: -4.108e-17 w: 8.480e-01, b: 1.11047e-16 Iteration 5000: Cost 1.25e-01 dj_dw: -6.047e-03, dj_db: 2.554e-17 w: 8.583e-01, b: 1.11023e-16 Iteration 6000: Cost 1.25e-01 dj_dw: -2.246e-03, dj_db: -5.218e-17 w: 8.622e-01, b: 1.11070e-16 Iteration 7000: Cost 1.25e-01 dj_dw: -8.341e-04, dj_db: 2.109e-17 w: 8.636e-01, b: 1.11020e-16 Iteration 8000: Cost 1.25e-01 dj_dw: -3.098e-04, dj_db: 1.776e-17 w: 8.641e-01, b: 1.11036e-16 Iteration 9000: Cost 1.25e-01 dj_dw: -1.151e-04, dj_db: -4.885e-17 w: 8.643e-01, b: 1.11069e-16 (w,b) found by gradient descent: ( 0.8644, 0.0000)
fig, (ax1, ax2) = plt.subplots(1, 2, constrained_layout=True, figsize=(12,4))
ax1.plot(J_hist[:100])
ax2.plot(1000 + np.arange(len(J_hist[1000:])), J_hist[1000:])
ax1.set_title("Cost vs. iteration(start)"); ax2.set_title("Cost vs. iteration (end)")
ax1.set_ylabel('Cost') ; ax2.set_ylabel('Cost')
ax1.set_xlabel('iteration step') ; ax2.set_xlabel('iteration step')
plt.show()

# Optimal values
print(f"Optimal value of weight is: {w_final}]\nOptimal value of bias is: {b_final}")
Optimal value of weight is: 0.8644087726498778] Optimal value of bias is: 1.1105671937627857e-16
# Plotting the results
plt.figure(figsize=(10, 5))
plt.scatter(house_price_data['size'], house_price_data['price'], color='red', marker='x')
sizes = np.linspace(min(house_price_data['size']), max(house_price_data['size']), 100)
normalized_sizes = (sizes - size_mean) / size_std
predicted_prices = linear_fn(normalized_sizes, w_final, b_final) * price_std + price_mean
plt.plot(sizes, predicted_prices, color='blue')
plt.title('House Size vs. Price with Fit Line')
plt.xlabel('Size in feet²')
plt.ylabel('Price in $1000\'s')
plt.show()

Predictions¶
Now that you have discovered the optimal values for the parameters $w$ and $b$, you can now use the model to predict housing values based on our learned parameters. As expected, the predicted values are nearly the same as the training values for the same housing. Further, the value not in the prediction is in line with the expected value.
def predict_house_price(house_size, w_final, b_final):
"""
Predict the house price for a given house size.
Parameters:
- house_size (float): The size of the house in square feet.
- w_final (float): Final weight from the trained model.
- b_final (float): Final bias from the trained model.
Returns:
- predicted_price (float): The predicted price of the house in the original price scale.
"""
size_mean = house_price_data['size'].mean()
size_std = house_price_data['size'].std()
price_mean = house_price_data['price'].mean()
price_std = house_price_data['price'].std()
# Normalize the input house size
normalized_size = (house_size - size_mean) / size_std
# Predict the normalized price using the model
normalized_price = w_final * normalized_size + b_final
# Unnormalize the predicted price
predicted_price = normalized_price * price_std + price_mean
print(f"Predicted price for a {house_size} sqft house is ${predicted_price:.2f}")
predict_house_price(1000, w_final, b_final)
predict_house_price(1200, w_final, b_final)
predict_house_price(2000, w_final, b_final)
Predicted price for a 1000 sqft house is $160.07 Predicted price for a 1200 sqft house is $179.87 Predicted price for a 2000 sqft house is $259.10
If you appreciate the content, Feel free to share the blogs.
References
- Supervised Learning: Comprehensive details about supervised learning can be found in the Scikit-learn documentation. Learn more about Supervised Learning.
- Linear Model - Regression: For an in-depth understanding of linear models in regression, refer to the Scikit-learn guide on linear regression. Read about Linear Model-Regression.
- Gradient Descent by Andrew Ng: This video by Andrew Ng provides a foundational explanation of the gradient descent algorithm. Watch the video on Gradient Descent.
- Machine Learning Specialization by Andrew Ng: Explore the Machine Learning Specialization on Coursera to dive deeper into machine learning concepts taught by Andrew Ng. Enroll in the Machine Learning Specialization.