Retrieval-Augmented Generation (RAG)
Introduction
Large Language Models are designed to read, understand, and generate text almost like humans, They have been trained on vast amounts of text data. Training such models takes longer and the data it’s trained on is pretty old.
LLMs are not aware of the specific data you often need for your AI-based application. To address this, we extend the models with new data by simply fine-tuning them. But now most models are very large and have already been trained on large amounts of data. Usually, Fine-tuning works only in very few scenarios. Fine-tuning performs well when we want our large language model to talk in a different style or tone.
While fine-tuning large models can be effective, it doesn’t always perform well with new data, a phenomenon I frequently observe in businesses. Large language models need a lot of good data, a lot of computer resources, and a lot of time for fine-tuning.
This guide, Will cover an interesting technique called Retrieval-Augmented Generation (RAG). This technique was introduced by Meta AI Research in 2021.
This approaches all the limitations faced with data, resources and latency.
Check out the Implementation code for a basic RAG is available in the Github repo.
I will also explain the code in this blog post.
General Idea of RAG
Retrieval-Augmented Generation in an AI-based application: Steps involved:
- User asks a query.
- System searches and looks for similar and related documents stored in the database that could answer the user’s query.
- System creates prompt for Large language model that includes the user’s questions, the relevant documents, and instructions for the LLM to use these documents as context to answer the user question.
- The system forwards a prompt to LLM.
- This LLM provides a response to the user’s query, based on the related documents/context supplied. The system generates this as the output.

I have explained RAG in simple terms, but I didn’t give much detail on how it works. now let’s go in-depth to understand how RAG works in detail
The proposed architecture by the authors of the paper titled Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks consists of two main parts.
- Retriever
- Generator
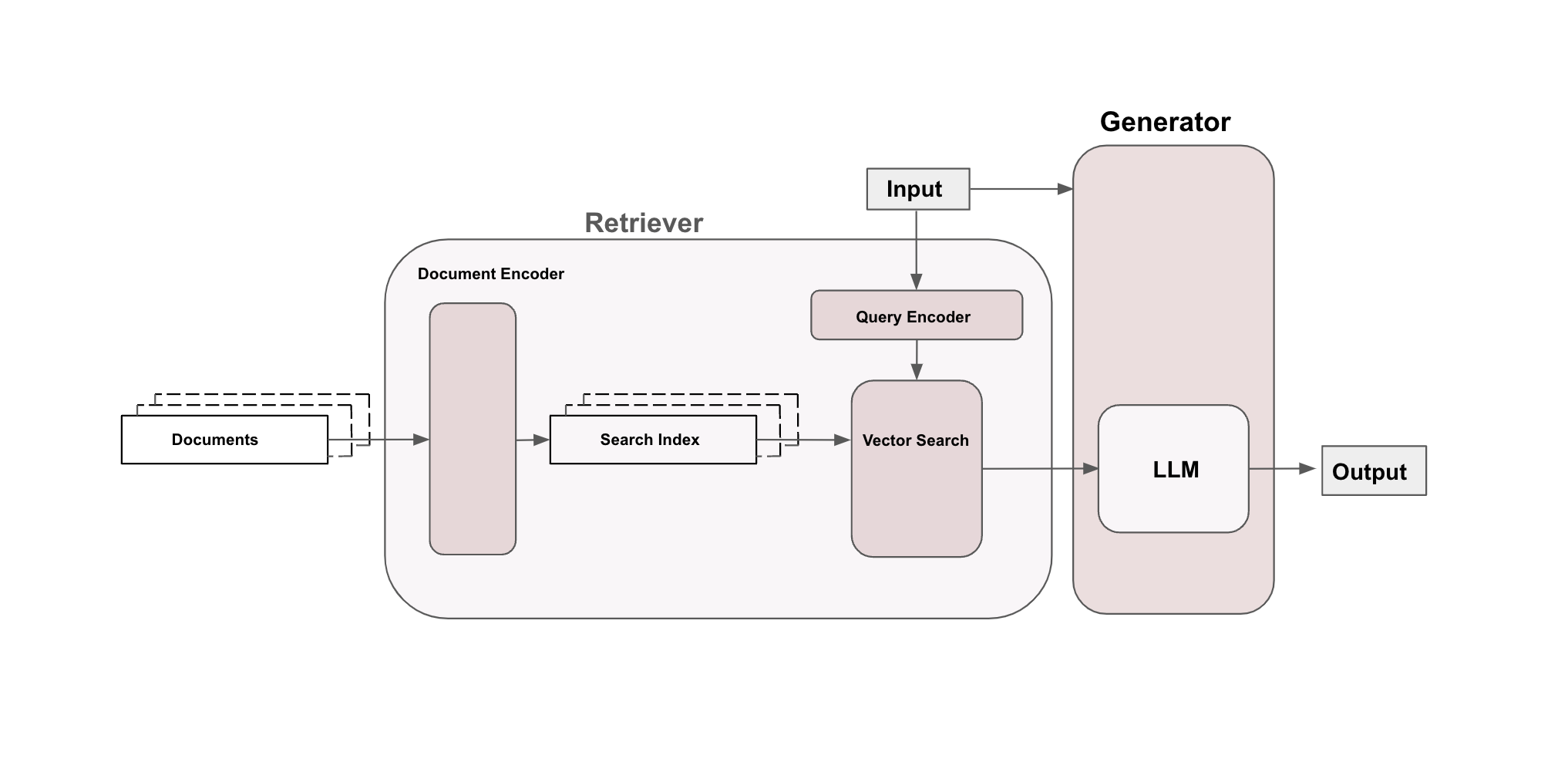
Here is the sketch of the architecture as presented inthe paper:
The Retriever transforms the input text into a sequence of vectors using a query encoder and It does the same for every document with the help of a document encoder and stores it in the search index. The system searches for document vectors related to the input/query vector, then turns those document vectors back into text and gives text as output.
The Generator takes the user’s query text and the matched document text creates a prompt by combining them, and asks a language model for a response to the user’s input based on the document information. The language model’s response is the system’s output.
In this architecture, both the Query Encoder and Document Encoder use transformer models. Generally, transformers consist of two main components: an encoder, which turns input text into a meaningful vector, and a decoder, which generates new text from that vector. However, in the described setup, the encoders are designed using only the encoder part of transformers. This choice is made because the goal is to transform text into numerical vectors, not to generate new text. On the other hand, the Large Language Model (LLM) in the generator uses a traditional encoder-decoder design, which is typical for tasks involving generating text based on input.
The paper author proposes two approaches for the implementation of RAG architecture:
RAG-sequence - In this approach, generates all output tokens that answer a user query using retrieved k documents.
RAG-token - We first find k documents and then use those documents to create the next word. Then, we find another k document to create the following word, and we keep doing this. This means we get many different groups of documents while making one answer to a question.
Now we understand the big picture of how things work in the RAG paper. But, not everything in the paper was done exactly as proposed.
The RAG sequence implementation is much used in the industry. Because It is simpler to implement than the RAG token, It is cheaper. It also gives us better results.
A query system generally consists of two steps:
- Retrieval: This step matches the user’s question to documents in the search index and gets the best matches. There are three main ways to find them:
- Keyword Search
- Vector Search
- Hybrid Search
- Ranking: It takes the documents that we found similar/relevant by retrieval system and re-arranges them, to improve their order of importance.
Let us understand each of them, Starting with different Retrieval types.
Keyword Search
In this approach, the way to find documents related to the user’s query is through "keyword search" This method uses the exact words from the user’s input to look for documents in an index that have matching text. It matches based on text, without using vectors.

The user’s text/query is parsed to figure out the search words. Then, It looks through the index for those words, and the most related documents will be returned from the search service with the help of a match score.
The keyword search approach works well when the keywords appear in the documents. To overcome issues we use vector search.
Vector Search
Consider an example, If you are looking for a pet online and search “small dog for adoption” and the documentation mentions “tiny puppy available,” it is “tiny puppy available,” keyword search might miss identifying that as a match. But, Vector search would know they match.
If we are searching for unstructured text, the Vector Search approach is very much suitable.
Here is the overview of RAG with vector search.

By the way, How do we get vectors? By using a pre-trained embedding model such as text-embedding-ada-002 to encode the input text and the documents. You can also use any embedding models. What are embeddings models? We use embedding models to translate the input query/text and the documents into embedding.
what is embedding? A vector of numbers that captures the meaning of text it encodes.
NOTE: Two pieces of text are similar when corresponding embedding vectors are similar.
Hybrid search
Hybrid search is a method that combines keyword and vector search techniques to improve search results. It conducts both searches separately and then merges the results. This approach is widely used in complex applications across various industries to enhance search capabilities.
There are many topics to cover according to the research paper, but in this article, I have provided a basic understanding of RAG.
Implementation of RAG
Now we understand the theory beyond the RAG. Now let’s dive into A simple implementation of RAG.
Two popular open-source libraries/frameworks that help us to build RAG applications with LLMs.
- LangChain
- LlamaIndex
I choose LlamaIndex for this article.
The goal of this project is to create a chatbot that users can interact with to get more information/suggestions about the products.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# pip install llama_index
# Import necessary libraries and modules
import os
from llama_index import VectorStoreIndex, SimpleDirectoryReader, StorageContext, ServiceContext, load_index_from_storage
from llama_index.llms import OpenAI
from llama_index.embeddings import OpenAIEmbedding
import openai
# Set the OpenAI API key. Replace 'your_api_key' with your actual OpenAI API key.
openai.api_key = 'sk-.....' # paste your api key.
# Initialize the language model and embedding model using OpenAI's GPT-3.5 Turbo.
llm = OpenAI(model='gpt-3.5-turbo', temperature=0, max_tokens=256)
embed_model = OpenAIEmbedding()
# Load documents from a specified directory. Replace "data" with your actual data directory path.
documents = SimpleDirectoryReader("data").load_data()
# Create a service context with default settings, specifying the LLM and embedding model.
service_context = ServiceContext.from_defaults(llm=llm, embed_model=embed_model)
# Create an index from the documents with the given service context.
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
# Convert the index into a query engine for executing search queries.
query_engine = index.as_query_engine()
# Define the user query. This can be any question or search term.
user_query = "What is the best noise-cancelling headphones available for under $200?"
# Perform the query using the query engine and print the response.
response = query_engine.query(user_query)
print(response)
You will get an output similar to when you run the above code.
1
2
3
4
5
>> QUESTION: "What is the best noise-cancelling headphones available for under $200?"
>> RESPONSE: "The Bose In-Ear Black Headphones - BOSEIE are the best noise-cancelling headphones available for under $200."
>> QUESTION: Suggest me the best macbook air under 2000$?
>> RESPONSE: The best MacBook Air under $2000 is the Apple MacBook Pro 2.4GHz Intel Core 2 Duo Silver Notebook Computer - MB470LLA. It has a 2.4GHz Intel Core 2 Duo Processor, 250GB 5400-RPM Serial ATA Hard Drive, 15.4' LED-Backlit Glossy Widescreen Display, Built-In iSight Camera, Built-In AirPort Extreme Wi-Fi And Bluetooth, NVIDIA GeForce 9600M GT Graphics Processor, Dual Display And Video Mirroring, Multi-Touch Trackpad, 85W MagSafe Power Adapter, Mini DisplayPort, Mac OS X v10.5 Leopard, and a Silver Finish.
Response will be based on the input data you provided to the system.
Conclusion
In this post, we have covered how RAG works, and the different search techniques that are commonly used. we finished by implementation of simple RAG using OpenAI.
I hope this encourages you to incorporate Retrieval Augmented Generation into your projects.
Thank you for reading, and best wishes for your AI endeavours.
Note
All Illustrations in this blog post are created by the author. You are free to use any original images from this post for any purpose, provided you give credit by linking back to this article.