Multi Label Classification Using Huggingface Transformer
This time, I have decided to work on multi-label classification problem, While I was searching for dataset, I found one in datahack.analyticsvidya. The problem statement was very simple, Topic Modeling for Research Articles
Given the abstract and titles for a set of research articles, predict the topics for each article included in the test set. Note that a research article can possibly have more than 1 topics. The research article abstracts are sourced from the following 6 topics:
- Computer Science
- Mathematics
- Physics
- Statistics
- Quantitative Biology
- Quantitative Finance
Evaluation Metric

We are set to go!
Exploratory analysis
Let us understand the dataset.
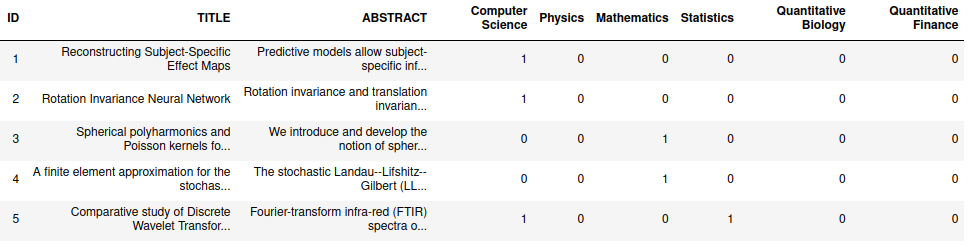
We have title and abstract as input columns, which represents the title of research paper, abstract of research paper. We also have topics to predict namely, Computer Science,Mathematics,Physics,Statistics,Quantitative Biology,Quantitative Finance.
How many articles do we have?
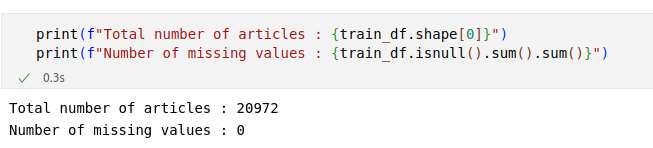
We have total of 20972 articles along with labels.
Distribution of labels
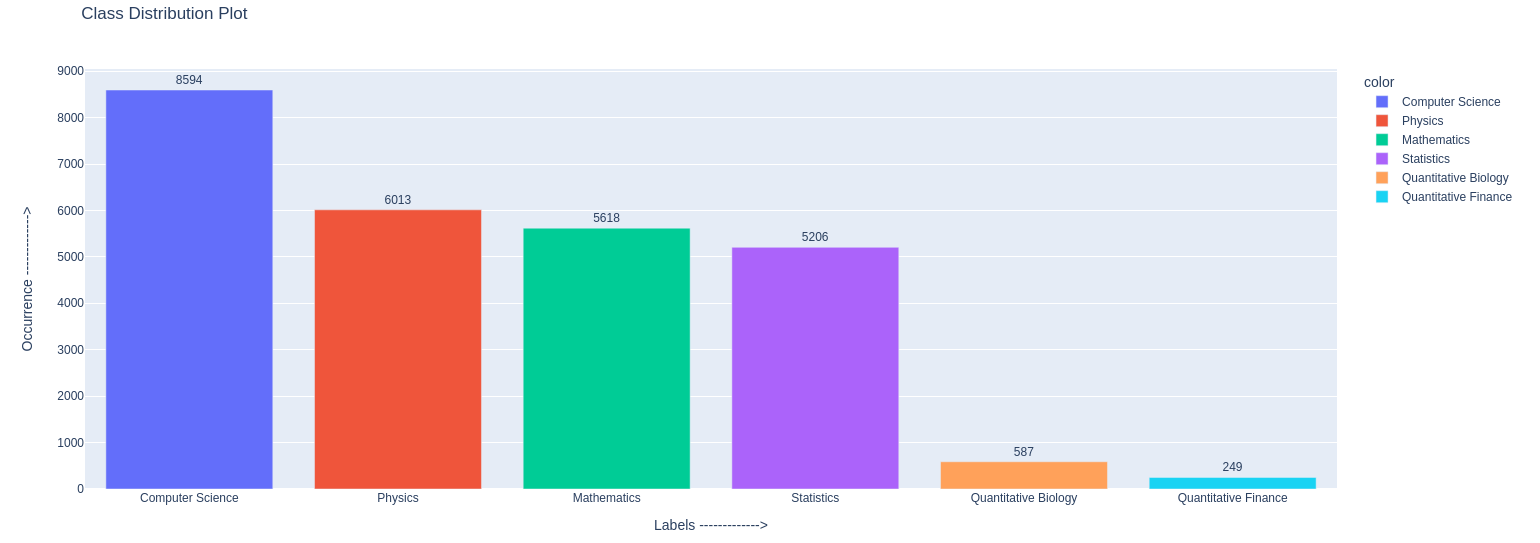
We can see the majority of articles are belongs to Computer Science and minority are from Quantitative Finance.
Are there any duplicate articles?

Great!, There are no repeated articles in the dataset.
Maximun sequence length of abstract

Counts of sequence lenght’s
Plotting how many times the sequence lenght has occured.
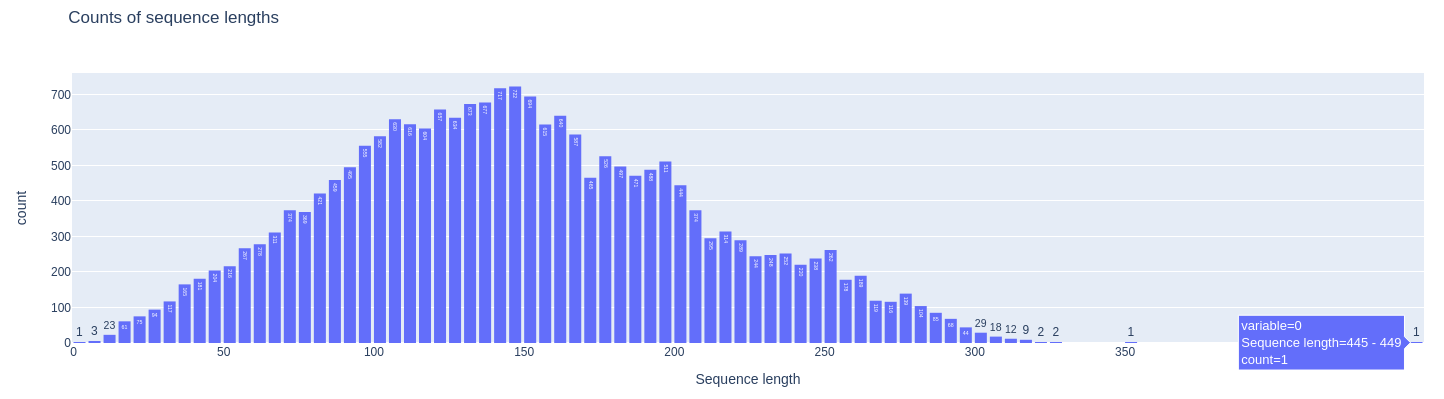
The maximun sequence length article is repeated only once.
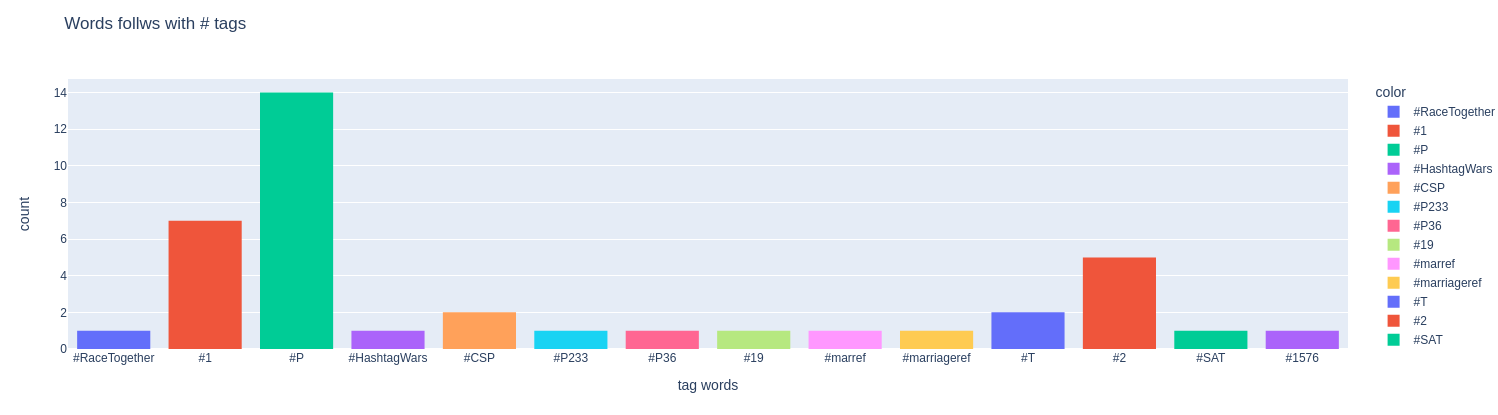
Are there any words follows with # tags?

Count of # tags occured in the abstract.
Representing ARTICLE text data in which the size of each word indicates its frequency or importance.
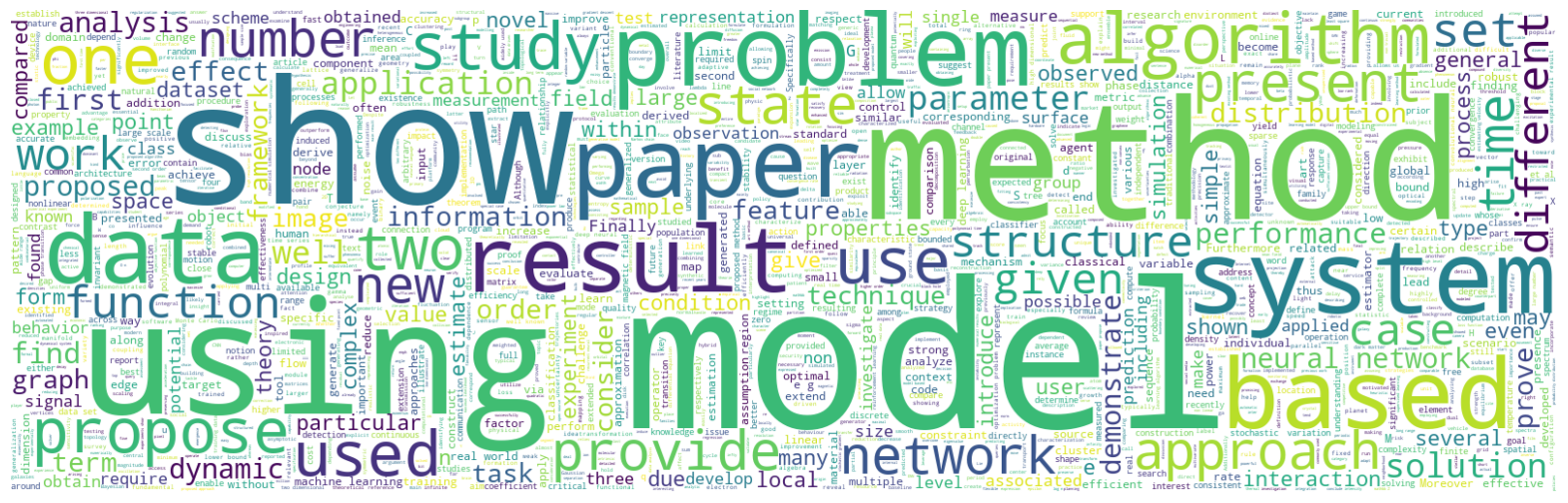
Few frequence or importance words in article are “show”,”model”,”using”,”method”,”result”,”system”,”problem” etc..
Representing TITLE text data in which the size of each word indicates its frequency or importance.

Few frequence or importance words in title are “Network”,”model”,”Data”,”based”,”Network”,”Learning”,”Neural Network” etc..
Count the most common words occured frequently
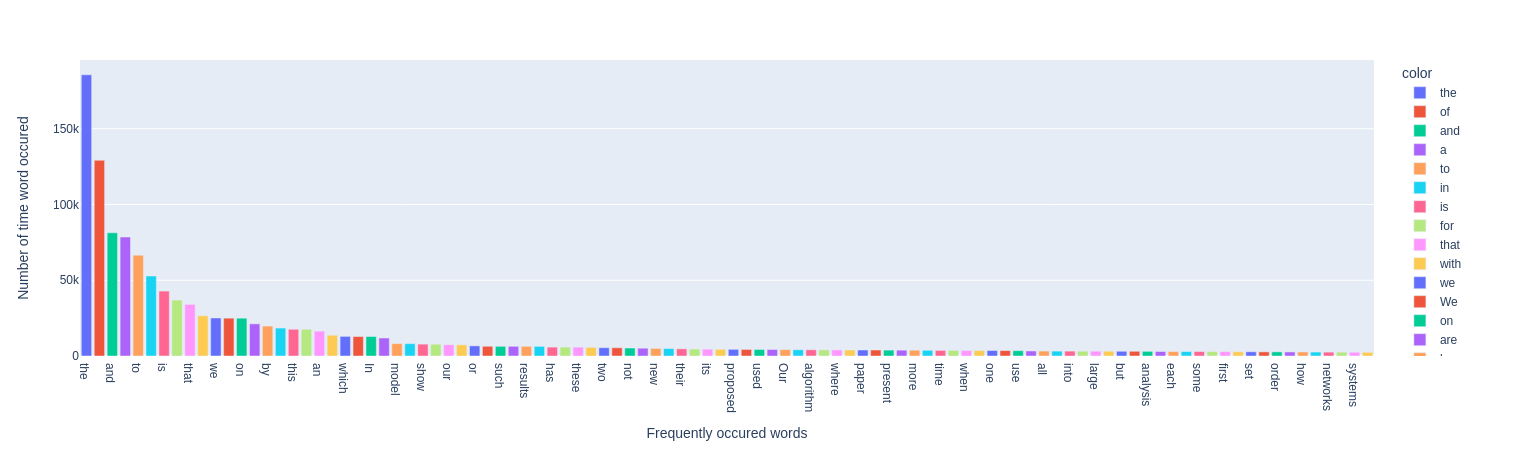
In all of the articles, A word “the” has repeated 185K+ times.
Tokenize the sentences.
There are many different ways of tokenizing sequence, In this article, I will show usage of huggingface pre-trained tokeniers.
The job of a tokenizer is to prepare the model’s inputs
Before we jump into coding part, Understand how tokenizer works.
Tokenization pipeline
When we call Tokenizer.encode or Tokenizer.encode_batch, the input text go through the following pipeline:
- normalization
- pre-tokenization
- model
- post-processing
You can checkout details what happens during each of those steps in detail here
Main class of hugginface Tokenizer : https://huggingface.co/docs/tokenizers/api/tokenizer
These tokenizers are also used in 🤗 Transformers.
In the following code, you can see how to import a tokenizer object from the Huggingface library and tokenize a sample text. There are many pre-trained tokenizers available for each model (in this case, BERT), We chose to use the base model, named “bert-base-uncased”.

The model needs special tokens to understand where a sequence starts and finishes. We need those special tokens to train the Neural Networks like Transformers.
you can find out each token and its respective ID. For example, the token “you” can be represented by the ID 2017. In another way, we can use the “encode” function to not only automatically convert a text to IDs but also add the special

first, we used the encode function to convert the text to IDs, and then used the “convert_ids_to_tokens” function to reconstruct the text and see the encoding function’s result. Again, if you compare these two lines results, you can see the ID 101 is translatable to [CLS] tokens (which is the same as
The next step is to use these IDs (that are meaningless) and make embedding vectors for each token (that will contain more information about each token) using algorithms like Word2Vec, But In this case, huggingface bert model takes output of BertTokenizers ie, input_ids,token_type_ids,attention_mask.
BERT base model (uncased)
This model is uncased: It does not make a difference between English and english.
This transformer model is pretrained on raw English text with no human labeling them in any way.
Know about few Bert configuration :
When you use bert model, The default configuration that results from instantiating a configuration is similar to the BERT configuration. In this BERT-paper default configuration are defined. even the huggingface transformer also follows the same configuration.
hidden_size : 768 – Dimensionality of the encoder layers and the pooler layer. num_hidden_layers : 12 – Number of hidden layers in the Transformer encoder.
To know information about all model outputs : https://huggingface.co/docs/transformers/v4.24.0/en/main_classes/output
Now using BertTokenizer, We tokenize the inputs and feed into the Bert model.
What parameters does BertTokenizer takes,
- text (str, List[str], List[List[str]]) – The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings.
- text_pair (str, List[str], List[List[str]]) – The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings (pretokenized string).
return_tensors (str or TensorType) – If set, will return tensors instead of list of python integers. Acceptable values are:
- ‘tf’: Return TensorFlow tf.constant objects.
- ‘pt’: Return PyTorch torch.Tensor objects.
- ‘np’: Return Numpy np.ndarray objects. for more parameters : https://huggingface.co/docs/transformers/internal/tokenization_utils

we can see that we got two output, last_hidden_state with size [1, 8, 768], and pooler_output shape of [1,768].
In bert model configutation, default hidden_size is 768, so we get the output of same size.
you can add final linear layer to decrease the size, based on your needs.
In this problem statment I have 6 labels, so I will use linear layer to decrease the size 768 to 6 and calculate loss..
Now it’s time to train model.
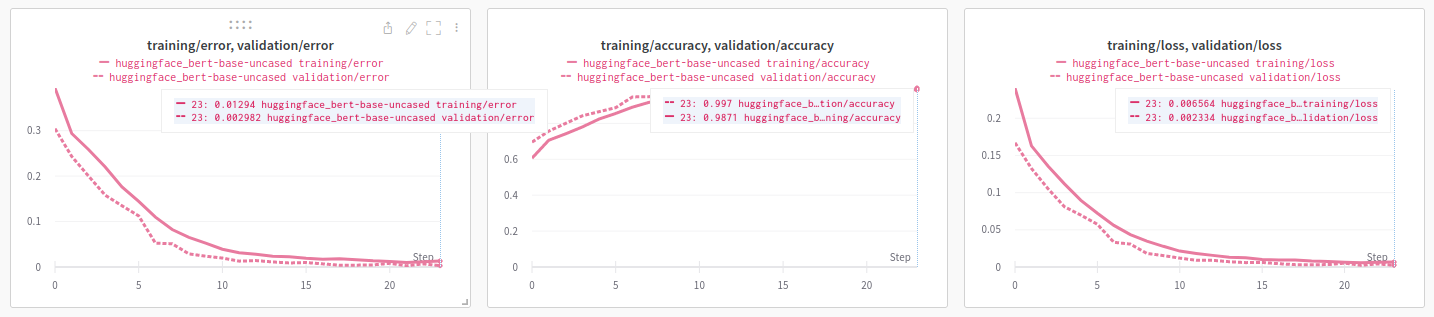
Learning curves
Good fit. The model has accuracy of 0.98. Which is really great.Thank to huggingface🤗.
You can checkout the learning curves wandb.
Tips:
It is typically advised to pad the inputs on the right rather than the left because BERT is a model with absolute position embeddings.
Masked language modelling (MLM) and next sentence prediction (NSP) objectives were used to train BERT. Although it is effective at NLU in general and at predicting masked tokens, it is not the best option for text generation.
Thanks for reading.
Source code : Github code
Blogs to read :